前言
前文NN编译栈之TVM研究报告深度分析TVM的源码结构,编译器特点。本文介绍TVM的当前缺陷以及如何修改源代码弥补缺陷并适配自己开发的神经网络加速器。不久会在GitHub上开源自己的适配修改工作并向TVM仓库提交新的版本。
现在主流的深度学习训练框架是Caffe/PyTorch/TensorFlow/MxNet等,对CPU/CUDA支持得很好。如果我们想把训练好的神经网络部署到其他的终端设备,这就带了几个挑战:
- 主流框架不支持ARM/FPGA/ASIC
- 嵌入式终端不需要训练功能,对前向推理的速度有极大的要求
- 嵌入式终端性能/内存/存储有限,主流框架的臃肿不适合部署
- 终端指令集,架构没有统一标准,开发部署难度很大
TVM 是深度学习系统的编译器堆栈。它旨在缩小以生产力为重点的深度学习框架与以性能和效率为重点的硬件后端之间的差距。 TVM与深度学习框架协同工作,为不同的后端提供端到端编译。TVM支持主流的深度学习前端框架,包括TensorFlow, MXNet, PyTorch, Keras, CNTK;同时能够部署到宽泛的硬件后端,包括CPUs, server GPUs, mobile GPUs, and FPGA-based accelerators。
如果我们想自己设计一款深度学习处理器(VTA)并兼容TVM编译栈,那么该如何开发?TVM编译器的扩展性如何?如何修改TVM编译器以适配自定义的深度学习处理器?
TVM针对VTA的编译流程
上文介绍,TVM定义了VTA的指令集,体系结构。为了实现硬件的通用化计算,VTA硬件参考RISC指令集,按照Fetch—>Load—>Compute—>Store模式,将所有操作划分到这种粒度的计算,不设计专用复杂的计算模式。
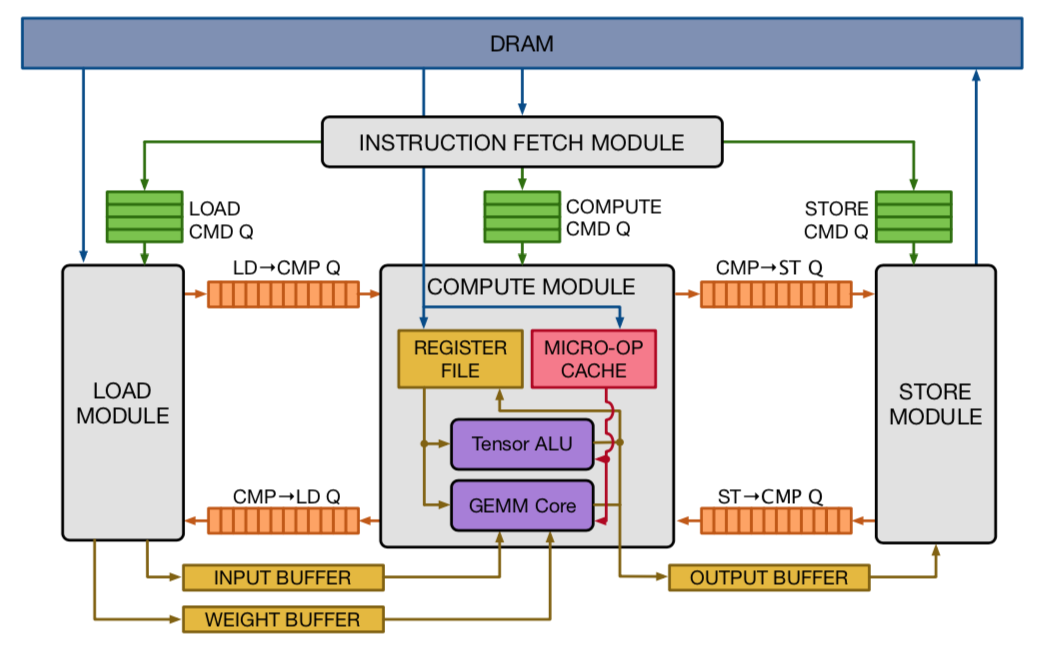
同时,TVM定义了VTA硬件的可重构约束。VTA主要对硬件的数据位宽,SRAM 大小,计算阵列大小进行配置,而不能更改大的计算架构,数据流,控制流等。
假设我们的VTA配置已经固定下来,TVM会按照如下流程编译VTA:
-
定义前端网络:对接MxNet。
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" # Name of Gluon model to compile # The `<code>start_pack</code><code> and </code><code>stop_pack</code>` labels indicate where # to start and end the graph packing relay pass: in other words # where to start and finish offloading to VTA. model = "resnet18_v1" start_pack = "nn.max_pool2d" stop_pack = "nn.global_avg_pool2d" ... dtype_dict = {"data": 'float32'} shape_dict = {"data": (env.BATCH, 3, 224, 224)} # Get off the shelf gluon model, and convert to relay gluon_model = vision.get_model(model, pretrained=True) -
将前端网络转为自己设计的AST Graph/Relay IR:“relay.frontend.from_mxnet“函数
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" # Start front end compilation mod, params = relay.frontend.from_mxnet(gluon_model, shape_dict) # Update shape and type dictionary shape_dict.update({k: v.shape for k, v in params.items()}) dtype_dict.update({k: str(v.dtype) for k, v in params.items()}) -
量化网络:这里应该采用的post-quantization方法,不需要重新训练或autotune。
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" # Perform quantization in Relay with relay.quantize.qconfig(global_scale=8.0, skip_conv_layers=[0]): relay_prog = relay.quantize.quantize(mod["main"], params=params) -
图打包和常量展开:预先计算常量节点,减少参数量和计算量。
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" # Perform graph packing and constant folding for VTA target if target.device_name == "vta": assert env.BLOCK_IN == env.BLOCK_OUT relay_prog = graph_pack( relay_prog, env.BATCH, env.BLOCK_OUT, env.WGT_WIDTH, start_name=start_pack, stop_name=stop_pack) -
VTA编译,生成Complied PackedFunc动态链接库。
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" with vta.build_config(): graph, lib, params = relay.build( relay_prog, target=target, params=params, target_host=env.target_host)VTA编译这步是我们研究的重点,分析TVM如何针对特定硬件进行编译,步骤如下:
- 将网络分解为针对VTA硬件的卷机计算图:
- 卷机topi.nn.conv2d
- 移位topi.right_shift
- bias相加topi.add
- 溢出处理my_clip
# tvm/vta/tests/python/integration/test_benchmark_topi_conv2d.py # Define base computation schedule with target: res = topi.nn.conv2d( data, kernel, (wl.hstride, wl.wstride), (wl.hpad, wl.wpad), (1, 1), layout, env.acc_dtype) res = topi.right_shift(res, 8) res = topi.add(res, bias) res = my_clip(res, 0, (1 << env.OUT_WIDTH - 1) - 1)-
我们来查看VTA的卷积是如何定义的:
- 传入数据(data,kernel)及卷机形状定义(strides,padding)
- 定义占位符(类似TensorFlow)reduce_axis
- 卷积张量定义tvm.compute
# tvm/vta/python/vta/top/vta_conv2d.py @autotvm.register_topi_compute(topi.nn.conv2d, 'vta', 'direct') def _declaration_conv2d(cfg, data, kernel, strides, padding, dilation, layout, out_dtype): """ Packed conv2d function.""" if not is_packed_layout(layout): raise topi.InvalidShapeError() assert dilation == (1, 1) d_i = tvm.reduce_axis((0, kshape[2]), name='d_i') d_j = tvm.reduce_axis((0, kshape[3]), name='d_j') k_o = tvm.reduce_axis((0, ishape[1]), name='k_o') k_i = tvm.reduce_axis((0, ishape[-1]), name='k_i') hstride, wstride = strides res = tvm.compute( oshape, lambda b_o, c_o, i, j, b_i, c_i: tvm.sum( pad_data[b_o, k_o, i*hstride+d_i, j*wstride+d_j, b_i, k_i].astype(out_dtype) * kernel[c_o, k_o, d_i, d_j, c_i, k_i].astype(out_dtype), axis=[k_o, d_i, d_j, k_i]), name="res", tag="conv2d_dense") cfg.add_flop(2 * np.prod(topi.util.get_const_tuple(oshape)) * kshape[2] * kshape[3] * ishape[1] * ishape[-1]) return res
- 将网络分解为针对VTA硬件的卷机计算图:
-
生成卷积层的调度方案
# tvm/vta/tests/python/integration/test_benchmark_topi_conv2d.py # Derive base schedule s = topi.generic.schedule_conv2d_nchw([res])-
我们看一下生成的调度器是什么样子:
- 绑定数据与对应buffer
- DMA搬运
- 循环分片:包括Channels、Height、Width
- 地址生成:数据加载存储地址
- 虚拟线程:掩盖访存延迟
# tvm/vta/tests/python/integration/test_benchmark_topi_conv2d.py print(vta.lower(s, [data, kernel, bias, res], simple_mode=True)) ##调度器部分代码 // attr [res_conv] storage_scope = "local.acc_buffer" // attr [data_buf] storage_scope = "local.inp_buffer" // attr [kernel_buf] storage_scope = "local.wgt_buffer" produce res { vta.coproc_dep_push(3, 2) vta.coproc_dep_push(3, 2) for (ic.outer, 0, 8) {//input channel // attr [iter_var(vta, , vta)] coproc_scope = 1 vta.coproc_dep_pop(2, 1) produce data_buf { VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), data, ((((ic.outer*196) + (i2.outer*98)) + (max((1 - (i2.outer*7)), 0)*14)) - 14), 14, ((9 - max((1 - (i2.outer*7)), 0)) - max(((i2.outer*7) - 6), 0)), 14, 1, max((1 - (i2.outer*7)), 0), 1, max(((i2.outer*7) - 6), 0), 0, 2) } produce kernel_buf { VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), kernel, ((i1.outer.outer*1152) + (ic.outer*9)), 9, 8, 72, 0, 0, 0, 0, 0, 1) } vta.coproc_dep_push(1, 2) // attr [iter_var(vta, , vta)] coproc_scope = 1 vta.coproc_dep_pop(2, 1) produce data_buf { VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), data, ((((ic.outer*196) + (i2.outer*98)) + (max((1 - (i2.outer*7)), 0)*14)) - 14), 14, ((9 - max((1 - (i2.outer*7)), 0)) - max(((i2.outer*7) - 6), 0)), 14, 1, max((1 - (i2.outer*7)), 0), 1, max(((i2.outer*7) - 6), 0), 144, 2) } produce kernel_buf { VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), kernel, (((i1.outer.outer*1152) + (ic.outer*9)) + 576), 9, 8, 72, 0, 0, 0, 0, 72, 1) } -
然后我们看一下调度器是什么计算的
- 加载默认的分片配置文件cfg
- 绑定数据与对应buffer:set_scope
- DMA:compute_at和cache_read
- 循环分片:apply
- 虚拟线程:split
- 指令生成:pragma
# tvm/vta/python/vta/top/vta_conv2d.py @autotvm.register_topi_schedule(topi.generic.schedule_conv2d_nchw, 'vta', 'direct') def _schedule_conv2d(cfg, outs): # 绑定数据与对应buffer cdata = s.cache_read(data, env.inp_scope, [conv2d_stage]) ckernel = s.cache_read(kernel, env.wgt_scope, [conv2d_stage]) # DMA cache数据 s[conv2d_stage].set_scope(env.acc_scope) # tile 循环分片 x_bo, x_co, x_i, x_j, x_bi, x_ci = s[output].op.axis x_co0, x_co1 = cfg['tile_co'].apply(s, output, x_co) x_i0, x_i1 = cfg['tile_h'].apply(s, output, x_i) x_j0, x_j1 = cfg['tile_w'].apply(s, output, x_j) s[output].reorder(x_bo, x_i0, x_co0, x_j0, x_co1, x_i1, x_j1, x_bi, x_ci) store_pt = x_j0 # set all compute scopes DMA for tensor in cache_read_ewise: s[tensor].compute_at(s[output], store_pt) s[tensor].pragma(s[tensor].op.axis[0], env.dma_copy) # virtual threading along output channel axes 虚拟线程 if cfg['oc_nthread'].val > 1: _, v_t = s[output].split(x_co0, factor=cfg['oc_nthread'].val) s[output].reorder(v_t, x_bo) s[output].bind(v_t, tvm.thread_axis("cthread")) # Use VTA instructions 指令生成 s[cdata].pragma(s[cdata].op.axis[0], env.dma_copy) s[ckernel].pragma(s[ckernel].op.axis[0], env.dma_copy) s[conv2d_stage].tensorize(x_bi, env.gemm) s[output].pragma(x_co1, env.dma_copy) return s
-
-
到这一步Complied PackedFunc已经生成好了,可以给VTA硬件编程使用
#"tvm/vta/tutorials/frontend/deploy_resnet_on_vta.py" vta.reconfig_runtime(remote) vta.program_fpga(remote, bitstream=None) -
前向测试:resnet18_v1分类结果并统计访存计算数据。
resnet18_v1 Execution statistics: inp_load_nbytes : 48864512 wgt_load_nbytes : 1695547392 acc_load_nbytes : 6723584 uop_load_nbytes : 36 out_store_nbytes: 1680896 gemm_counter : 1655808 alu_counter : 286160 resnet18_v1 prediction #1: tiger cat #2: Egyptian cat #3: tabby, tabby cat #4: lynx, catamount #5: weasel
总的来说,TVM针对前端网络和VTA的编译,调用流程如下。其中重点是调度方案的生成,对不同架构的VTA适配最需要的就是定义对应架构的调度方案。
- 定义前端网络
- 将前端网络转为自己设计的AST Graph/Relay IR
- 量化网络
- 图打包和常量展开
- VTA编译,生成Complied PackedFunc动态链接库
- 生成卷积层的调度方案
- VTA硬件编程
- 前向测试
自定义VTA架构:TVM的缺陷与性能瓶颈
自定义深度学习处理器VTA架构可以分为两种设计方案:
-
魔改VTA架构,指令集:需要对TVM编译器作大规模源码更改,目前TVM的针对VTA的编译是固定指令集与架构,扩展性较差。
-
保持VTA架构不变,修改配置:修改硬件的数据位宽,SRAM 大小,计算阵列大小进行配置,而不能更改大的计算架构,数据流,控制流等。
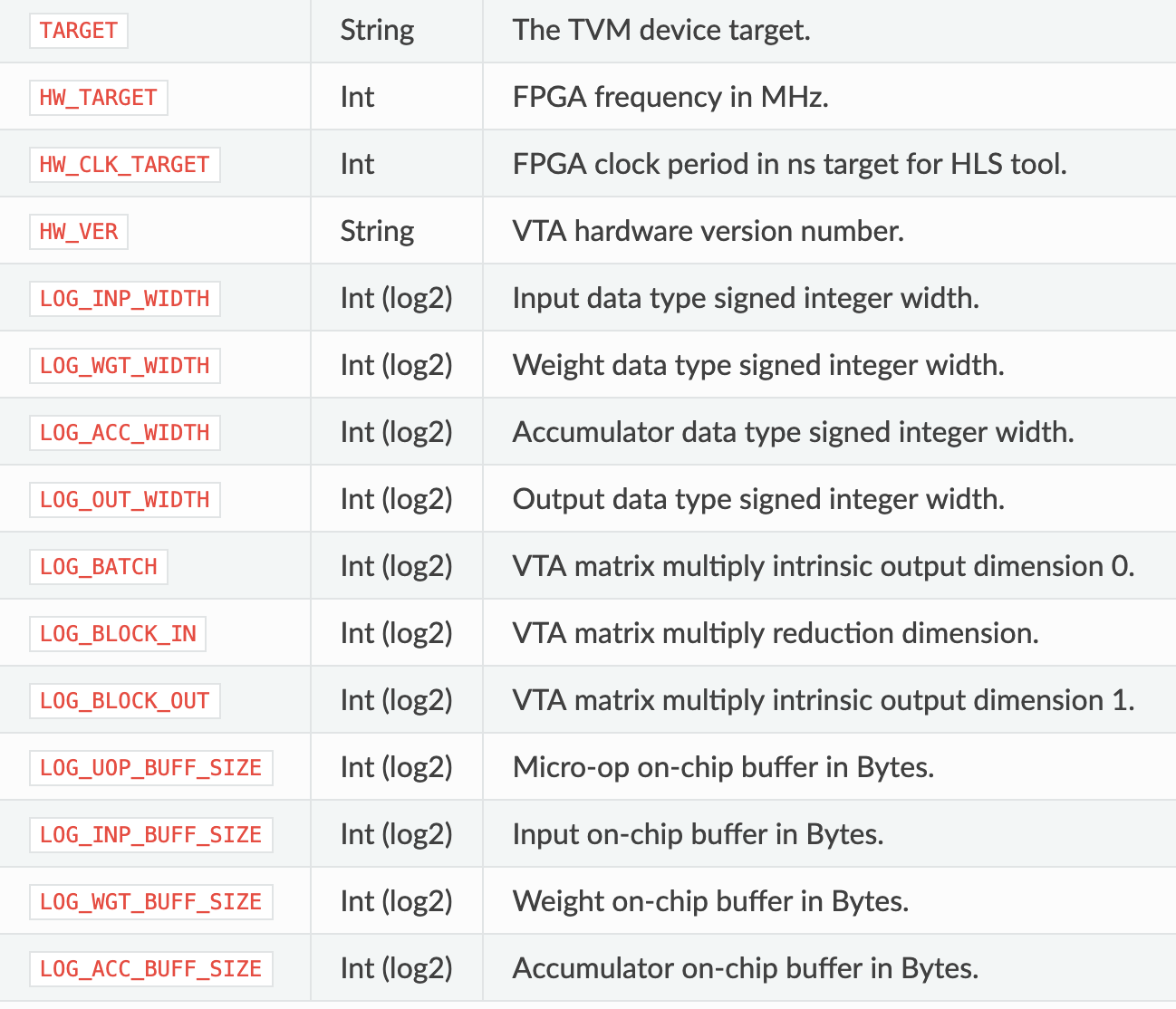
本文的目的是分析TVM的缺陷与瓶颈,所以先从最简单的第二种方案研究。VTA架构配置更改在"tvm/vta/config/vta_config.json",参考前文进行对应的修改。
{ "TARGET" : "sim", "HW_VER" : "0.0.1", "LOG_INP_WIDTH" : 3, "LOG_WGT_WIDTH" : 3, "LOG_ACC_WIDTH" : 5, "LOG_BATCH" : 0, "LOG_BLOCK" : 4, "LOG_UOP_BUFF_SIZE" : 15, "LOG_INP_BUFF_SIZE" : 15, "LOG_WGT_BUFF_SIZE" : 18, "LOG_ACC_BUFF_SIZE" : 17 }
TVM缺陷与瓶颈
缺陷一:SRAM配置灵活性差
VTA配置SRAM大小的时候不是任意可配的,假如固定计算位宽和计算规模,理论上讲BUFF_SIZE只要大于一个最小值就可以。但其实不是这样,BUFF_SIZE必须固定,计算方式本文推定如下。总的来说,SRAM配置不够灵活,如果芯片/FPGA资源过小或过大,都不好兼容TVM。
VTA_UOP_BUFF_SIZE=VTA_LOG_UOP_BUFF_DEPTH+VTA_LOG_UOP_WIDTH-3=15
VTA_INP_BUFF_SIZE=VTA_LOG_INP_BUFF_DEPTH+VTA_LOG_BLOCK_IN+VTA_LOG_INP_WIDTH-3=
VTA_WGT_BUFF_DEPTH=VTA_LOG_WGT_BUFF_DEPTH+VTA_LOG_BLOCK_OUT + VTA_LOG_BLOCK_IN + VTA_LOG_WGT_WIDTH - 3
VTA_ACC_BUFF_DEPTH=VTA_LOG_ACC_BUFF_DEPTH+VTA_LOG_BATCH + VTA_LOG_BLOCK_OUT + VTA_LOG_ACC_WIDTH - 3- VTA_LOG_UOP_BUFF_DEPTH必须固定为15,没有什么道理可讲。TVM固定UOP_BUFF_DEPTH必须为8192
- LOG_INP_BUFF_SIZE/LOG_ACC_BUFF_SIZE必须保持上面的计算方式,不可大于计算值。
- LOG_WGT_BUFF_SIZE可小于计算值,灵活性还算可以。
缺陷二:计算阵列配置僵硬
如果修改计算阵列,比如16×16到32×32或者64×64,那么VTA编译依然按照16×16的调度方案编译新的架构,修改的配置毫无意义。同时新的架构性能比16×16还差。如下图所示,32×32访存比16×16高出95倍,带来极大的性能损失。
resnet18_v1:16x16 架构
Execution statistics:
inp_load_nbytes : 5549568
wgt_load_nbytes : 12763136
acc_load_nbytes : 30720
uop_load_nbytes : 1540
out_store_nbytes: 1680896
gemm_counter : 6623232
alu_counter : 572320
resnet18_v1 prediction for sample 0
#1: tiger cat
#2: Egyptian cat
#3: tabby, tabby cat
#4: lynx, catamount
#5: weaselresnet18_v1:32x32架构
Execution statistics:
inp_load_nbytes : 48864512
wgt_load_nbytes : 1695547392
acc_load_nbytes : 6723584
uop_load_nbytes : 36
out_store_nbytes: 1680896
gemm_counter : 1655808
alu_counter : 286160
resnet18_v1 prediction for sample 0
#1: tiger cat
#2: Egyptian cat
#3: tabby, tabby cat
#4: lynx, catamount
#5: weasel缺陷三:网络支持少
虽然TVM宣称支持主流的深度学习框架及大量神经网络模型,但是当前TVM(*本文指VTA,ARM/CUDA没有深入研究)支持/适配的网络较少,目前本文在不改变任何代码的情况下只跑通了默认的resnet18_v1。支持其它网络模型较少的原因如下:
-
Relay量化目前只支持有限的操作类型
-
VTA目前只支持有限的操作类型
-
Relay量化Bug:如果部署resnet50_v1,会报如下错误:
Check failed: lhs->dtype == dtype (int8 vs. int32)参考Quantization failed for ResNet50;ZihengJiang解决修复了这个问题并提交到GitHub上Refactor quantization codebase and fix model accuracy
Separate quantization code base into different files: partition.cc, annotate.cc, realize.cc Change rewrite_for_vta to extra partition pass and enable it by default Change annotation.force_cast(x) to annotation.cast_hint(x, dtype) Remove qconfig.store_lowbit_output and enable it by default Fixed accuracy of models like mobilenet: resnet18_v1(8-16bit): 69.29% resnet18_v1(8-32bit): 69.29% resnet34_v1: 73.33% resnet50_v1: 74.78% resnet101_v1: 75.66% mobilenetv2_1.0: 66.64%
TVM源码修改之静态调度搜索算法
VTA的架构配置僵化与性能瓶颈原因在于TVM编译器僵化的调度方案。僵化原因如上文VTA编译流程所说,VTA采用写死的分片配置文件cfg,无论你怎么修改架构,分片方案都不回变。所以性能瓶颈如此引来。
# tvm/vta/python/vta/top/vta_conv2d.py
@autotvm.register_topi_schedule(topi.generic.schedule_conv2d_nchw, 'vta', 'direct')
def _schedule_conv2d(cfg, outs):那么有解决方案吗?TVM的设计方案是AutoTVM,一种在线的调度空间搜索算法:
- 修改VTA配置
- 联机FPGA:不支持仿真模式
- 对调度方案进行迭代,大概1000次(可配置)
- 找寻在所有迭代方案中性能最优的调度器。
这种方案不支持仿真模式,因为仿真迭代速度太慢(仿真 VS FPGA类似CPU VS GPU)。本问对这种方案表示不解,原因如下:
- 如果是做芯片ASIC,设计阶段的在线迭代会很麻烦。
- 如果硬件VTA的架构固定,调度方案是确定解。完全可以实现一套静态的调度方案,根据VTA配置在编译阶段就可以确定最优的调度。
本文实现了这种静态调度搜索算法,针对前端网络与VTA硬件在编译阶段搜索最优的调度器。实现性能的大幅提升,不需要FPGA这种在线AutoTVM迭代方案。编译时间的增加可忽略不计。
resnet18_v1:32x32架构 静态调度搜索算法
Execution statistics:
inp_load_nbytes : 5743104
wgt_load_nbytes : 12730368
acc_load_nbytes : 29696
uop_load_nbytes : 829
out_store_nbytes: 1680896
gemm_counter : 1655808
alu_counter : 286160
resnet18_v1 prediction for sample 0
#1: tiger cat
#2: Egyptian cat
#3: tabby, tabby cat
#4: lynx, catamount
#5: weasel如上图搜索,本文实现的搜索算法实现32×32架构比16×16结构性能提高四倍,访存保持不变。彻底解决TVM编译器的固有缺陷与性能瓶颈。不久会更新解释算法原理与实现细节,并在GitHub上开源自己的静态调度搜索算法并向TVM仓库提交新的版本。
awesome
感谢博主分享
请问静态搜索算法的代码可以公开,让我们参考下么?谢谢
后续会公开的
TVM目前在VTA上还有很多问题,我差不多都解决了就会公开
谢谢,期待。我们目前也在做TVM/VTA的相关开发和扩展,希望可以多向你请教。
请问博主了解怎样将auto_scheduler方法应用到vta中吗?
请问博主是否已经公布搜索的方法,如果是的话能否发个链接我学习一下,谢谢