前言
深度学习/神经网络应用日益广泛,多终端部署形成常态。从CPU、ARM、GPU到专用的神经网络加速器/深度学习处理器,不同的终端/不同的体系结构引起神经网络的碎片化;为每一款设备特别是专用的加速芯片部署深度学习是一件费力不讨好的事情;同时近年来,虽然CNN加速器在学术上和产业上火热,但不同的研究人员/企业在CNN加速器上使用不同的指令集,不同的体系结构,没有统一的标准使开发人员在终端上部署是七国八制,各自为政的。所以一款支持前端,各种后端,统一结构/指令集,扩展方便的NN编译栈在NN生态上的构建有着举足轻重的影响力,这就是TVM的魅力。
现在主流的深度学习训练框架是Caffe/PyTorch/TensorFlow/MxNet等,对CPU/CUDA支持得很好。如果我们想把训练好的神经网络部署到其他的终端设备,这就带了几个挑战:
- 主流框架不支持ARM/FPGA/ASIC
- 嵌入式终端不需要训练功能,对前向推理的速度有极大的要求
- 嵌入式终端性能/内存/存储有限,主流框架的臃肿不适合部署
- 终端指令集,架构没有统一标准,开发部署难度很大
这时需要一款软件编译栈,上接前端主流深度学习框架,后接各种终端;同时满足轻量级,高性能,高度扩展与灵活性,开发容易等要求。TVM 是深度学习系统的编译器堆栈。它旨在缩小以生产力为重点的深度学习框架与以性能和效率为重点的硬件后端之间的差距。 TVM与深度学习框架协同工作,为不同的后端提供端到端编译。TVM支持主流的深度学习前端框架,包括TensorFlow, MXNet, PyTorch, Keras, CNTK;同时能够部署到宽泛的硬件后端,包括CPUs, server GPUs, mobile GPUs, and FPGA-based accelerators。
本文深度分析TVM的源代码(主要是FPGA-based accelerator/VTA方面),给出一篇研究报告,总结TVM的几个实现特点:
- 对接前端的神经网络模型配置文件,将前端网络转为自己设计的AST Graph/Relay IR;后端编译都基于这个Graph/Relay IR。这类似于实现一个通用的编译器,将C++/JAVA/Python等语言转换为自己的编译型语言IR;然后基于IR实现一个高性能的后端程序部署。
- 实现NN的Tensor Operator Libray:不同的后端采用不同的实现方式。
- 根据后端硬件将前端网络编译为Complied PackedFunc生成动态链接库,用于后端执行。
- RunTime和Driver加载Complied PackedFunc调用硬件执行推理计算。
- 在HalideIR/LLVM框架/思想上实现编译系统。
前端的分离方式便于TVM兼容主流的深度学习框架,后端的编译运行分离使后端只需要部署一个轻量级的TVM(只包括RunTime和Driver)。这种思想能够兼顾通用性与性能。同时TVM在VTA(NN加速器)上的设计了一套通用的类RISC指令集,体系结构。TVM的整体思想与最终目标就是通用,形成一个深度学习全栈生态;但目前TVM实现的效果如何,让我们走近源代码分析一番。
调研目标
本文着重分析TVM的Relay IR 层,编译,VTA(NN加速器)源代码;ARM/CUDA部分目前不在源代码分析范围内。
- 明确TVM层次结构,掌握TVM的用法,工作原理,支持的软硬件框架
- 分析TVM源码设计与实现,对TVM的工作框架有清晰地、层次化的认识
- 研究TVM论文、文档与源码,提炼出TVM的设计思想;包括整体设计思想,Relay、VTA,并细化到JIT、Complier、Hardware Design等设计理念。
- 评估TVM从前端到后端的性能,着重于VTA硬件的实现指标
- 整体评估基于TVM设计加速器的可行性
- 具体分析TVM的细节实现,包括VTA Hardware,JIT Diver,Complier等。
- 评估设计或修改加速器所需的软件改动,包括修改难度、工作量
- 综合以上,得出基于TVM编译栈生态设计自己的处理器,部署神经网络的可行性及成熟度分析。
TVM介绍
TVM是一个端到端的深度学习工具链,能够高效地把前端深度学习模型部署到CPUs、GPUs和专用的加速器上。TVM具有强大的兼容能力和扩展性,支持主流的深度学习前端框架,包括TensorFlow, MXNet, PyTorch, Keras, CNTK;同时能够部署到宽泛的硬件后端,包括CPUs, server GPUs, mobile GPUs, and FPGA-based accelerators。
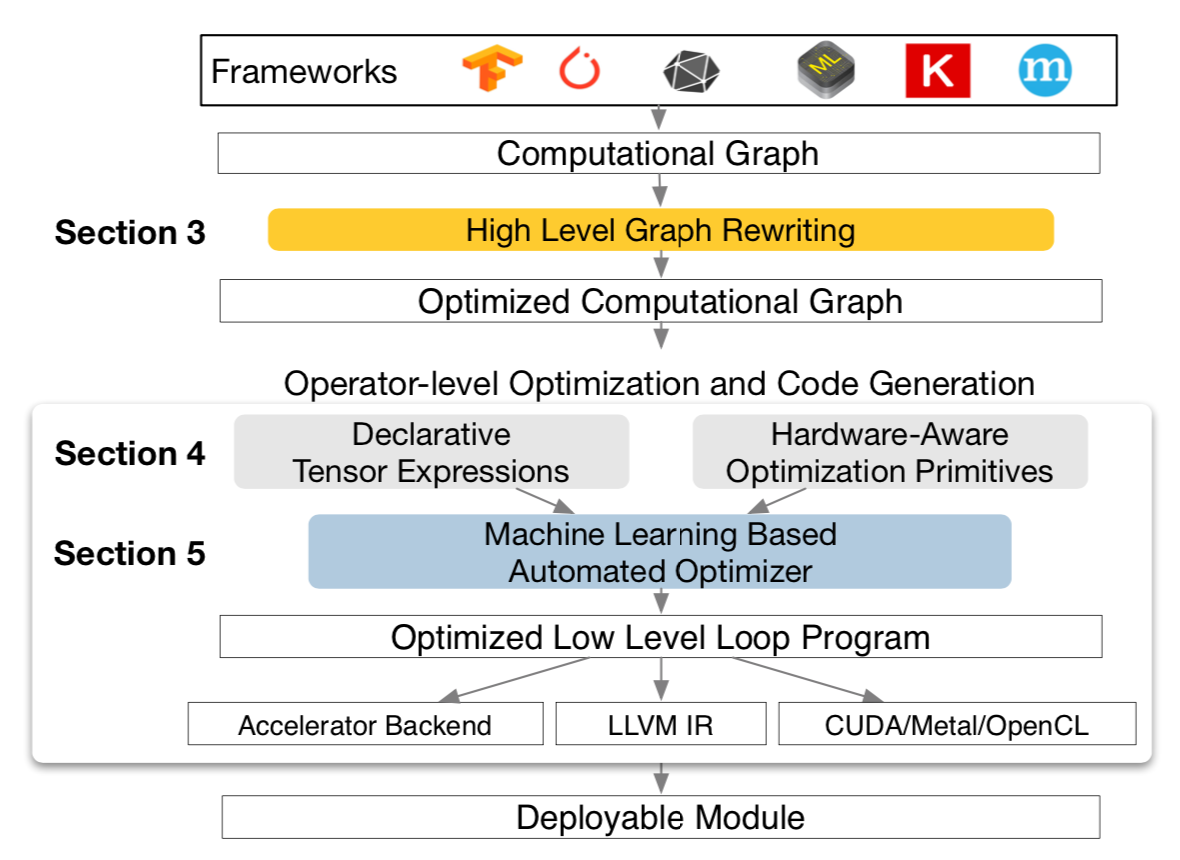
TVM架构如下:
- 导入前端深度学习模型 CNN model configuration and parameters,生成计算图
- 重构原始计算图,基于operator-level优化图的计算
- 基于Tensor张量化计算图,并根据后端进行硬件原语级优化
- 根据优化目标探索搜索空间,找到最优解
- 生成硬件所需指令、数据并部署到硬件上
Tvm注意点:
-
TVM只做前向计算包括量化,不对网络进行训练
-
硬件是预先可配置的,编译优化部署的时候硬件需保持固定。
-
可以部署TVM Runtime System到嵌入式设备上(SOC),实现CPU与VTA之间的自动交互和实时运行环境。
TVM源码架构
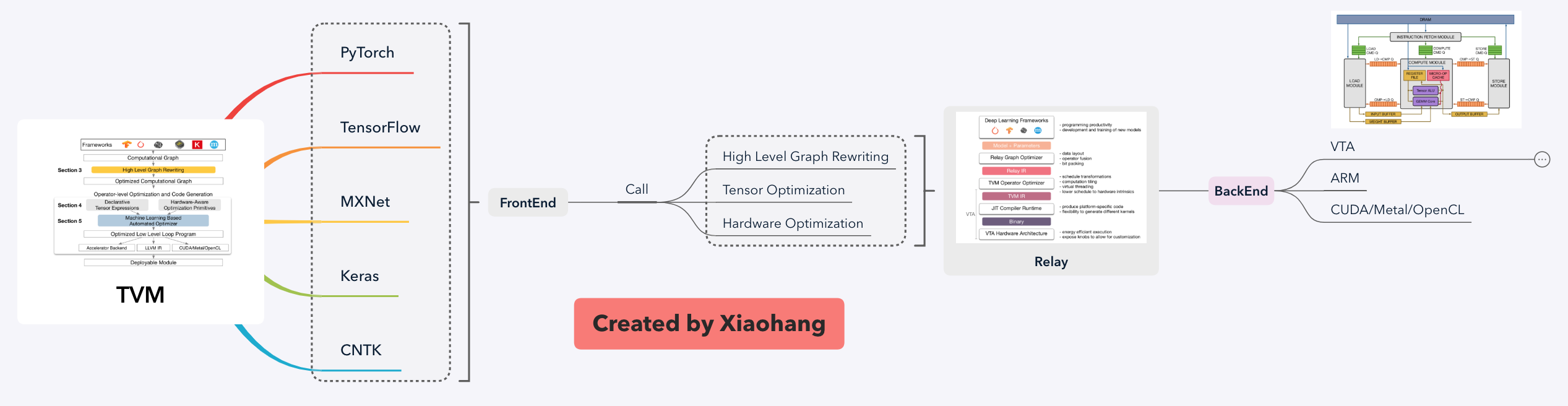
TVM 源代码由三层构成,包括FrontEnd接口、Relay优化和BackEnd部署。目前着重研究BackEnd VTA层级和与硬件相关的Relay部分。设计上三层应该互不影响,各自独立;但源代码分析中,Relay层糅合了与硬件无关的图优化和与VTA相关的调度生成,没有分得很开。
FrontEnd
支持主流的深度学习前端框架,包括TensorFlow, MXNet, PyTorch, Keras, CNTK。目前TVM可以继承到PyTorch框架中优化、训练,而不是单纯地调用CNN模型接口。
Relay
根据具体硬件对原始计算图进行重构、张量优化、数据重排等图优化操作。源代码分析中,Relay层比较杂,干的事情比较多,既对接上层的图优化又对接硬件的调度器。
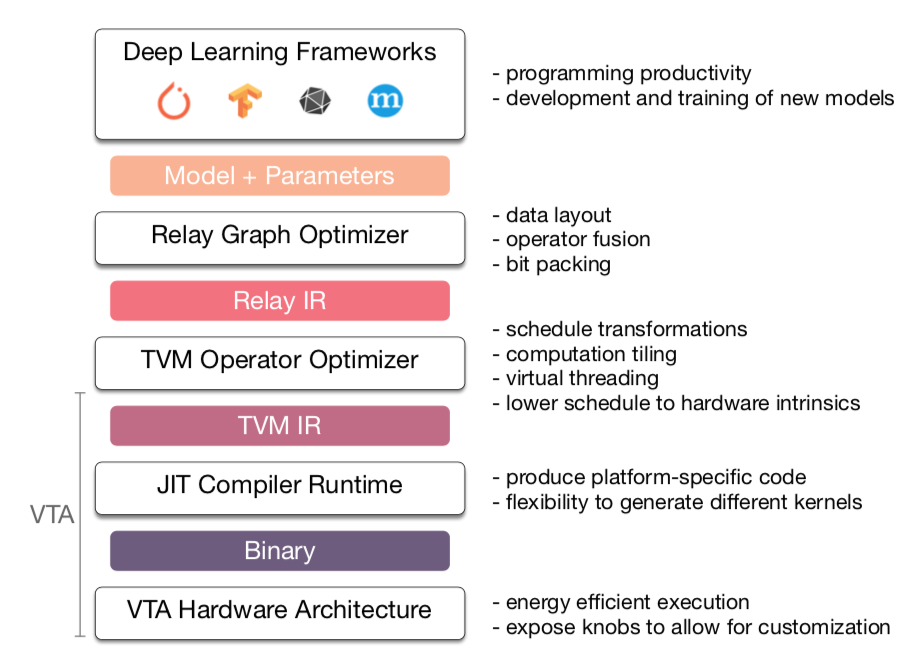

BackEnd
后端支持ARM、CUDA/Metal/OpenCL及加速器VTA。
- 生成硬件所需指令流与数据打包
- 一个CPU与VTA的交互式运行环境:包括driver、JIT。
VTA实现原理及设计思想提炼
整体结构
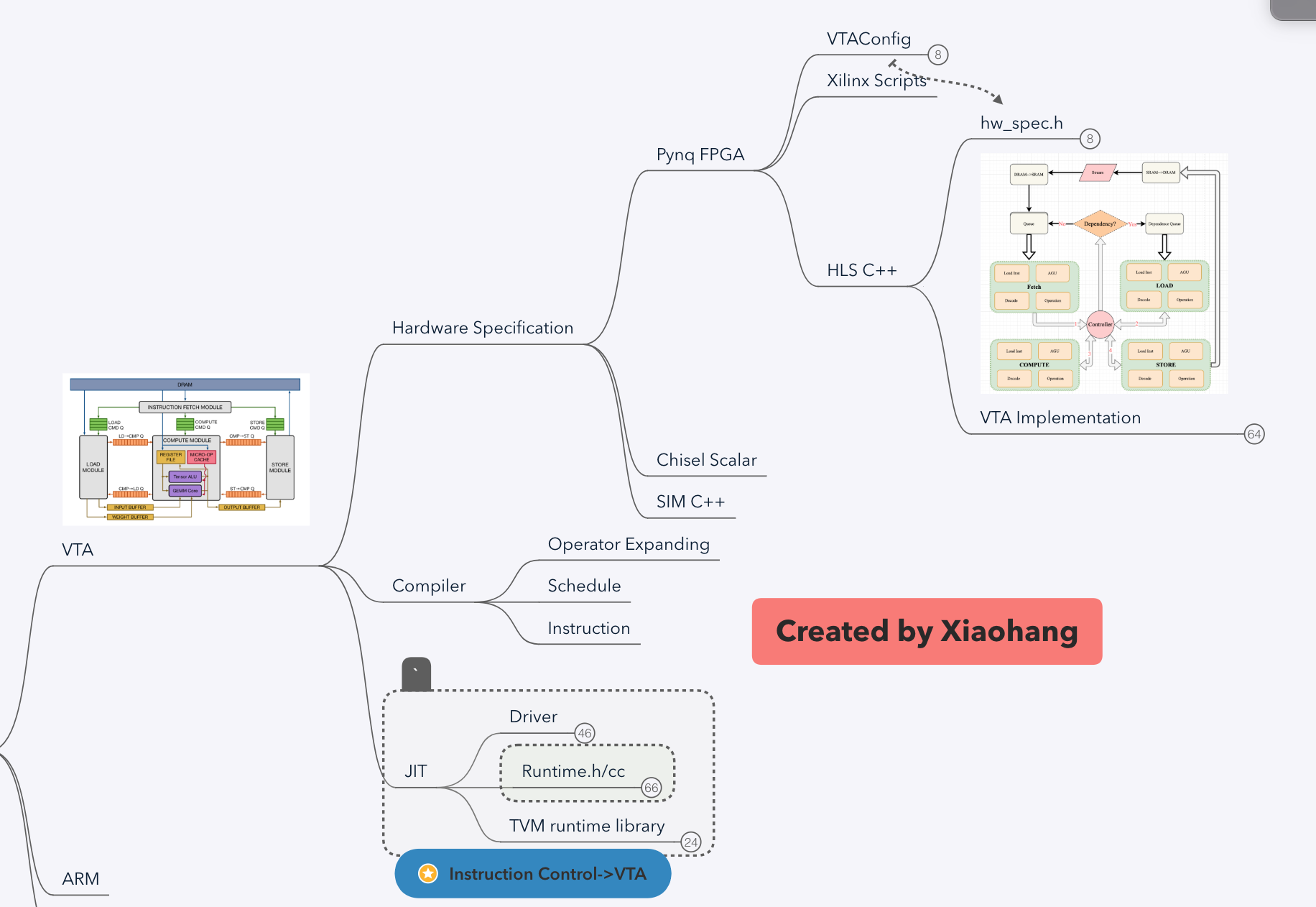
VTA源代码架构有三个部分组成:
- 硬件实现:包括硬件源代码、硬件配置文件
- 编译器:以operator或func级打包计算图生成调度器,以及编译出硬件执行指令
- JIT:软硬件交互运行环境
- Driver:CPU与VTA的通信与控制驱动
- Runtime:CPU对VTA的实时运行控制
- TVM runtime library:VTA runtime的基本库,主要是具柄的定义
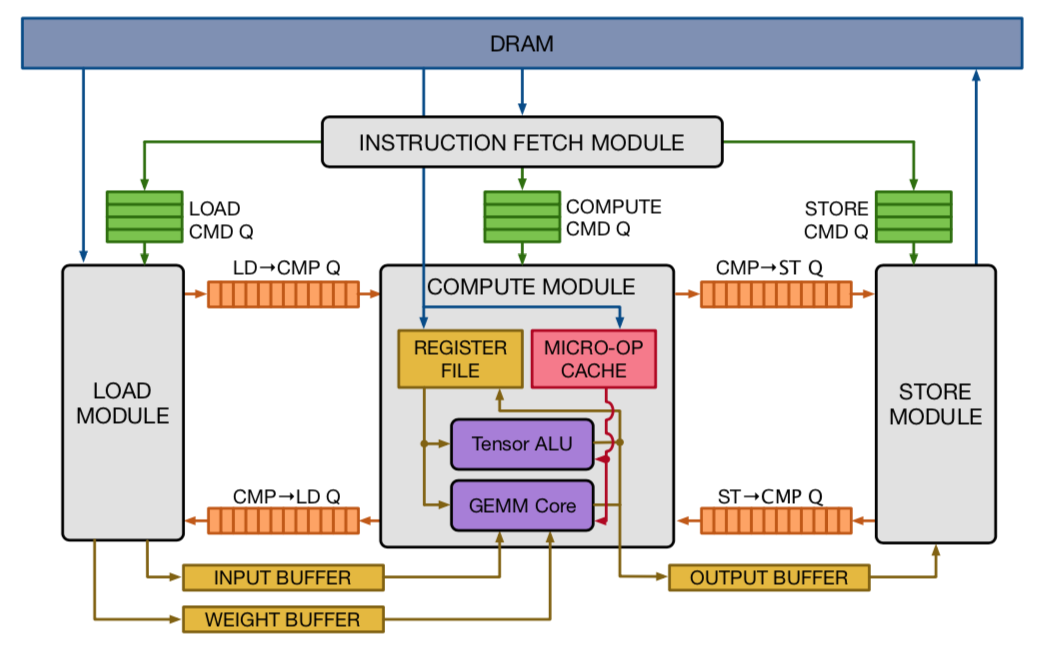
VTA Hardware
为了实现硬件的通用化计算,VTA硬件参考RISC指令集,按照Fetch—>Load—>Compute—>Store模式,将所有操作划分到这种粒度的计算,不设计专用复杂的计算模式。在牺牲一定性能的情况下,尽可能兼容更多的深度学习网络。
指令集
VTA指令分为四大类:
-
Fetch:从DRAM取指到片上指令SRAM
- load 指令buffer
- GEMM指令buffer
- Store指令buffer
-
LOAD:从DRAM取数据到片上SRAM
- inp buffer和wgt buffer
- uop buffer (源码实现在compute 中)
- Acc buffer放bias(源码实现在compute 中)
-
Compute:加载SRAM数据到计算单元并执行GEMM或ALU计算
- ALU:执行vector的计算Min、Max、ADD、MUL、SH
- GEMM:执行Tensor乘法
-
Store:从SRAM存储数据到DRAM
数据流
VTA relies on dependence FIFO queues between hardware modules to synchronize the execution of concurrent tasks. The figure below shows how a given hardware module can execute concurrently from its producer and consumer modules in a dataflow fashion through the use of dependence FIFO queues, and single-reader/single-writer SRAM buffers. Each module is connected to its consumer and producer via read-after-write (RAW) and write-after-read (WAR) dependence queues。

The pseudo-code above describes how a module executes a given instruction predicated on dependences with other instructions. First, the dependence flags within each instruction are decoded in hardware. If the instruction has an incoming RAW dependences, execution is predicated upon receiving a RAW dependence token from the producer module. Similarly, if the task has an incoming WAR dependence, execution is predicated upon receiving a WAR dependence token from the consumer module. Finally when the task is done, we check for outgoing RAW and WAR dependences, and notify the consumer and producer modules respectively.
控制流
按照Fetch—>Load—>Compute—>Store模式去计算:
- CPU把数据和指令放到DRAM
- Fetch和Load分别将指令和数据从DRAM搬运到SRAM
- CPU会提前计算好一部分AGU地址uop放到DRAM,然后被搬运到uop Sram
- Compute译码指令根据指令参数执行对应的GEMM或ALU计算;计算结果放回到acc/out sram。
- Store将计算结果从SRAM放回到DRAM
- CPU取出计算结果并准备下次计算数据,返回第一步
Inp buffer和Out buffer之间没有数据交换,固定buffer in/out。控制逻辑会处理数据/指令依赖以及memory latency hiding。
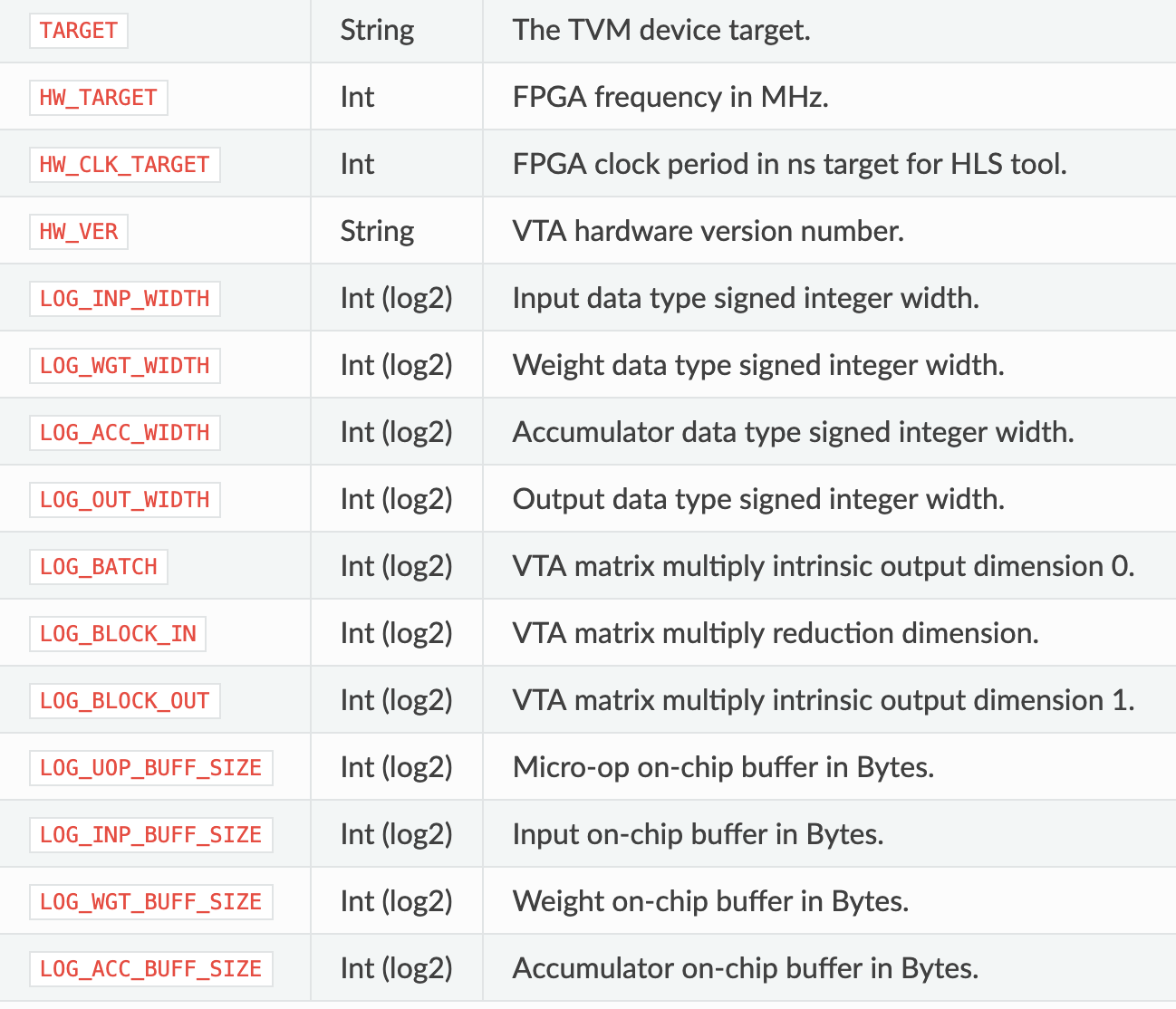
VTA Config
VTA主要对硬件的数据位宽,SRAM 大小,计算阵列大小进行配置,而不能更改大的计算架构,数据流,控制流等;同时TVM根据已配置好的VTA执行编译工作,而不会在编译阶段在线生成硬件代码。
Pyng HLS
VTA采用高层次综合C++实现Xilinix Pynq FPGA的部署,包含配置文件,Vivado HLS 脚本,HLS C++硬件实现三部分组成。
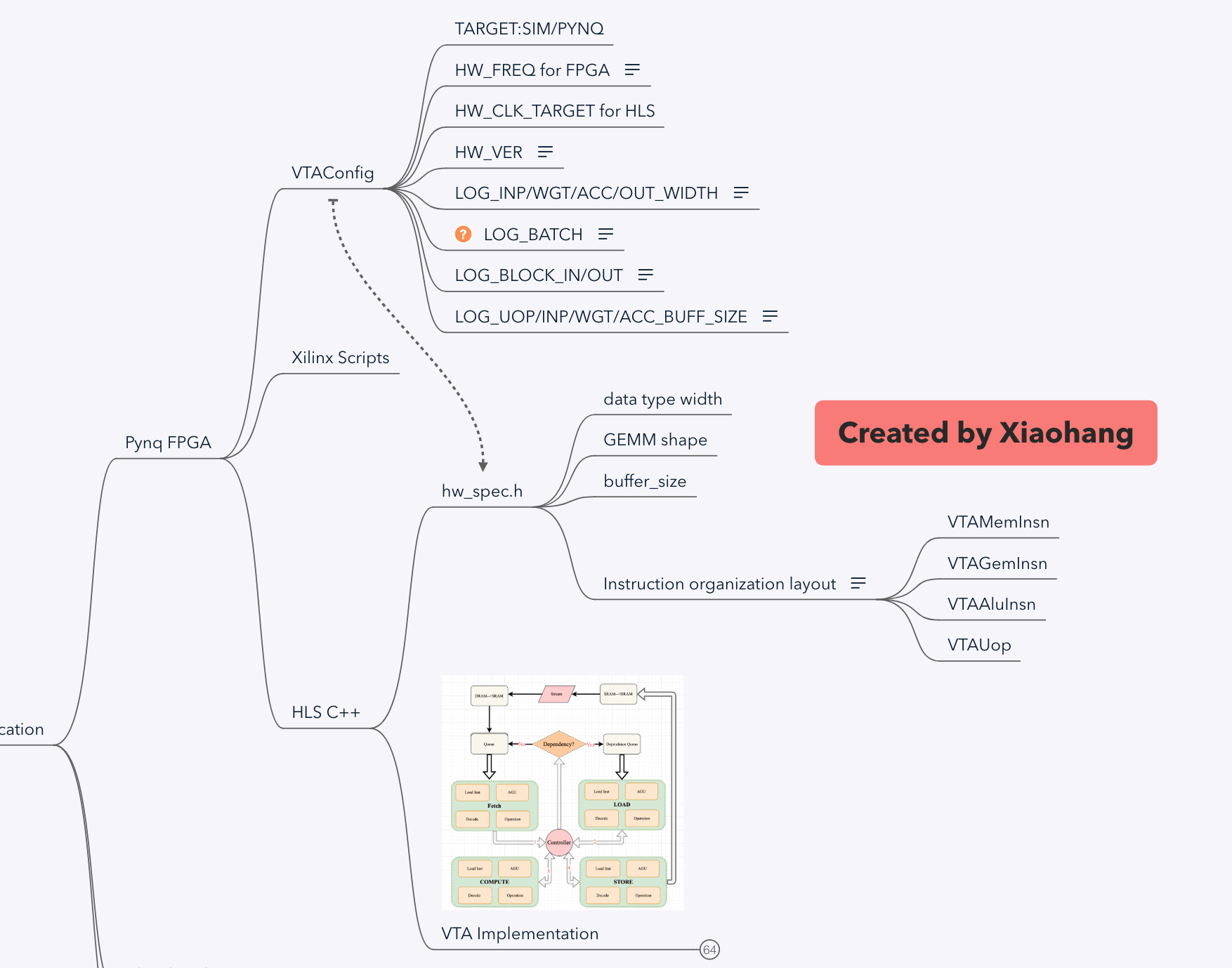
Hw_spec和VTA Implementation构成HLS 实现的主体:
-
hw_spec.h: 数据及指令定义
-
根据VTA Config 定义数据宽度,GEMM规模,SRAM大小
-
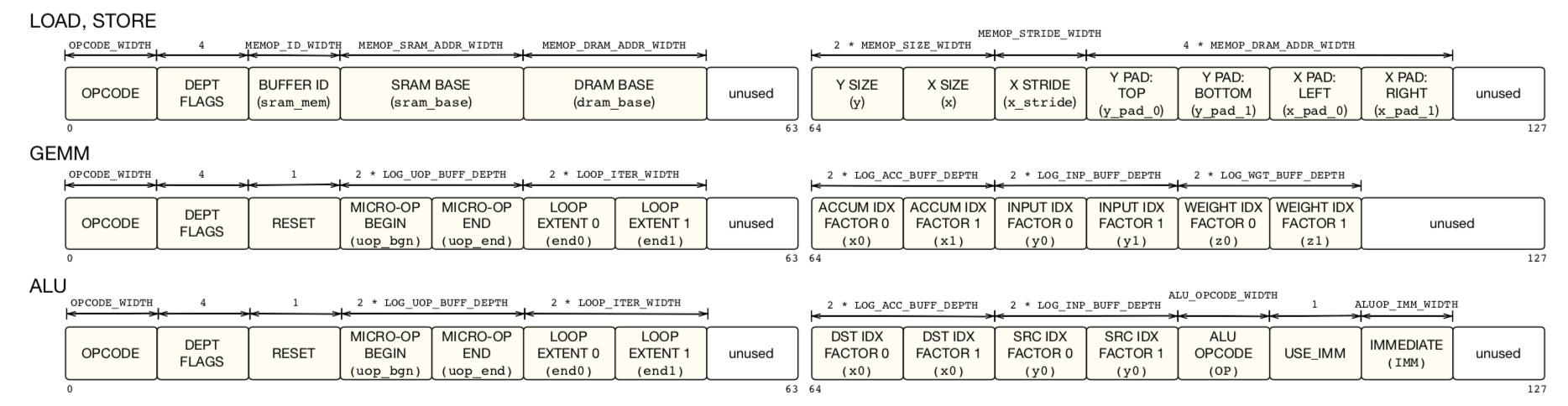
定义指令layout(指令关键字段的排列顺序,如下面GEMM layout所示)
-
// GEMM Layout // _____________________________|_type______________| // arg 0: opcode | opcode_T | // arg 1: pop_prev_dependence | bool | // arg 2: pop_next_dependence | bool | // arg 3: push_prev_dependence | bool | // arg 4: push_next_dependence | bool | // arg 5: reset_reg | bool | // arg 6: uop_bgn | uop_idx_T | // arg 7: uop_end | uop_idx_T | // arg 8: iteration count ax0 | loop_T | // arg 9: iteration count ax1 | loop_T | // arg a: accum idx factor ax0 | acc_idx_T | // arg b: accum idx factor ax1 | acc_idx_T | // arg c: input idx factor ax0 | inp_idx_T | // arg d: input idx factor ax1 | inp_idx_T | // arg e: weight idx factor ax0 | wgt_idx_T | // arg f: weight idx factor ax1 | wgt_idx_T
-
-
VTA Implementation:硬件实现包括Stream、fetch、load、compute、store五大模块及VTA顶层控制。

- Stream:定义CPU与VTA之间的数据接口/数据流。
- fetch:将指令从DRAM根据译码分类分别搬运到SRAM三个buffer中:load_queue,gemm_queue,store_queue。
- load:从load_queue中读取load指令,译码并计算对应地址;从DRAM上搬运inp和weight到SRAM上inp_mem和wgt_mem中。同时数据的padding工作通过在数据传输时对inp_mem写零完成。
- compute:从gemm_queue中读取计算指令,译码计算对应地址;从DRAM上搬运uop(计算所需的部分数据,权重地址)和bias到SRAM;从SRAM中加载数据和权重,根据译码计算GEMM或者ALU。其中计算的核心数据流为:
- Input SRAM—>Input Register
- Input Register—> Computing Unit
- Result—>Out Register/Out SRAM
- Out Register—> Out SRAM
- Store:将计算结果从SRAM—>DRAM
- VTA:以上模块的控制逻辑实现。
- 封装stream:包括instuction queue和dependency queue。
- 实例化SRAM
- 取值
- 根据依赖调度存储和计算(依赖参考上文数据流中的dependence)
硬件设计思想提炼
VTA的核心思想在于将计算划分到一个通用的细腻度的计算结构OperationWrapper(我命名的):
- Load Inst:加载Operation对应指令
- Decode:译码
- AGU:计算Operation所需要的DRAM或SRAM地址
- Operation:利用Operation对应的硬件计算资源执行操作
无论是Fetch、load、compute、store等较大粒度的操作都可以利用OperationWrapper分解到更细粒度的四个步骤,这和我们传统的设计方法不同。举例,传统设计是将芯片分为DMA—>Load—>Compute—>Store四个模式,每个模式单独去设计一套尽量通用的操作单元,去匹配软件算法;同时每个模式不会再分解到一个更通用的细腻度结构;OperationWrapper将Fetch—>Load—>Compute—>Store中每个模式都分解为Load—>Decode—>AGU—>Operation,即使是传统认为Load/Store已经是最小粒度,TVM依然再次分解到OperationWrapper。这有点像RISC中再RISC的思想(个人认为)。
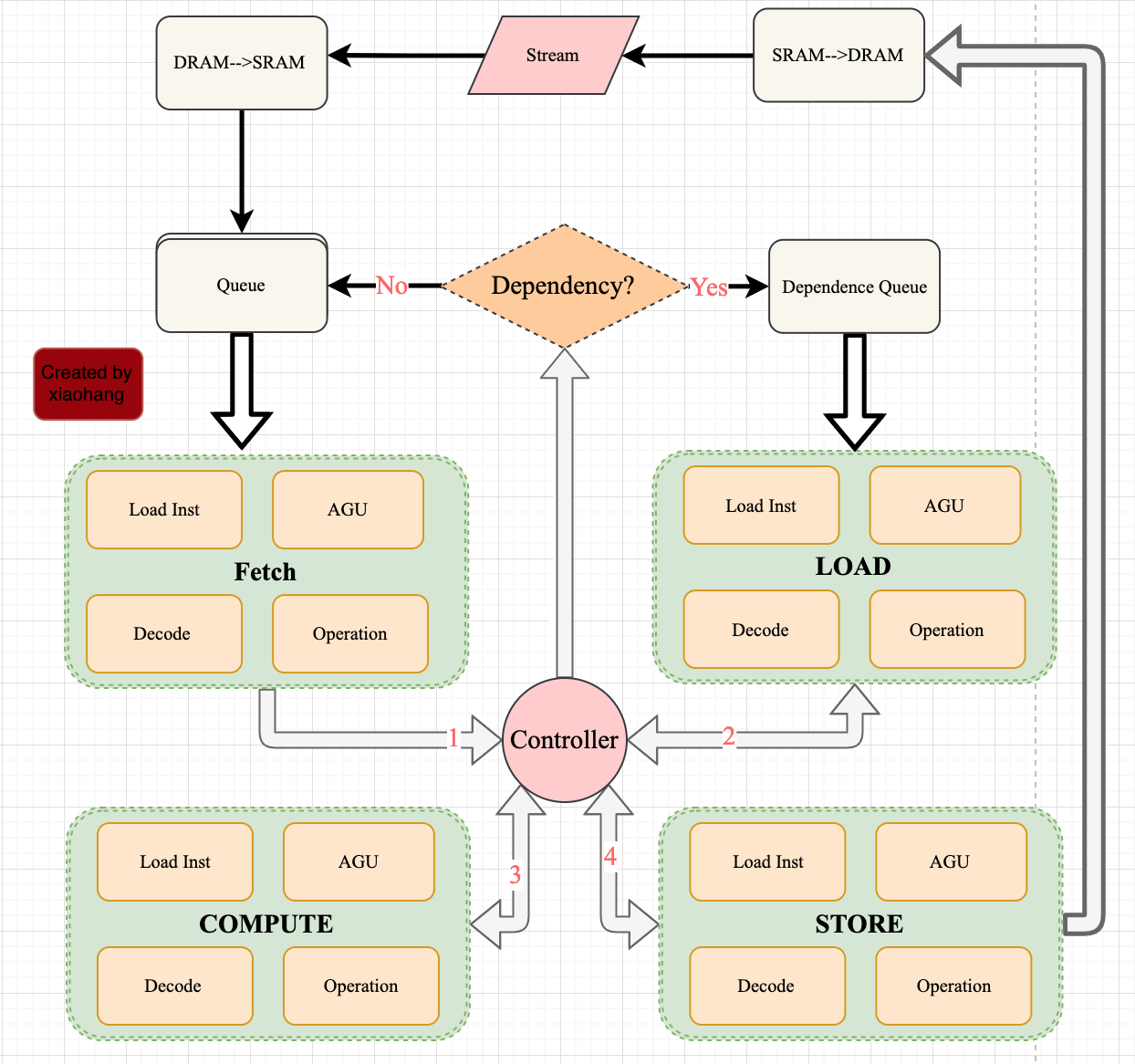
另外,传统方法设计一个统一的AGU负责所有的地址计算;而TVM通过OperationWrapper将统一的AGU分解到每个模块,让每个模块负责一个更细粒度的AGU。这种方式能够加强AGU的通用性。
VTA这种OperationWrapper的思想将硬件进一步分解到更加通用的细粒度模式,比起传统方法通用型更强。
VTA的第二个核心思想是利用Stream传输并通过同步控制解决指令与数据的依赖性(有点类似操作系统中的设计理念),让CPU与VTA的通讯、传输、控制变得更向操作系统级靠拢,可能也是为了TVM的通用性考虑。
以下内容待更新
Chisel Scalar
SIM C++
Xilinx Scripts
VTA JIT
Driver
Runtime
TVM Runtime Library
VTA Complier
参考文献
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
VTA: A Hardware-Software Blueprint for Flexible Deep Learning Specialization
博主文章写的非常好,如果能把其中的英文缩写的全称写出来就更完美了。加油!!,期待后续文章。
你好,请问以下博主这个文章可以标明出处转载到GiantPandaCV微信公众号吗?
可以