前言
全国容错计算学术(CFTC)会议通过高质量的前沿技术报告、学术报告、专题讨论等形式,就测试与容错技术等领域的最新研究进展和发展趋势开展广泛、深入的学术交流。欢迎从事测试理论与技术、容错计算、可信计算、硬件安全、集成电路设计自动化及相关领域研究工作的产学研各界专家、学者以及学生代表踊跃投稿与参会。
本人参加第十八届全国容错计算学术会议(CFTC2019),从参加的报告中总结本次会议的亮点:
- 新一代图计算架构:基于数据流和缓存感知的图计算模式
- 容错深度学习处理器:探索CNN的容错性并设计实时监测的深度学习处理器
- 可重构计算架构:基于软件定义数据路径的可重构计算架构
- 存算一体化:存内计算与近存储计算的新模式
- 开源EDA:围绕RISC-V建立中国的开源EDA生态
A novel computing model for binary network with time-domain signal
Tao Wang,southeast university
- On chip Sram with logic units
- 96.2 TOPS/w
- 精度受局部工艺波动影响;如果没有波动,精度与软件一致
A study of Fault Tolerance Method of Wireless On-Chip Network Token Mechanism
欧阳一鸣, 合肥工业大学
- 无线片上网络
- 令牌MAC(媒体访问控制)机制
- 片上环境的容错令牌MAC机制
Approximate Computing for Convolutional Neural Networks based on Quantified Fault Tolerance
Chengjun Wu, Southeast University
- 近似计算 低bit近似加法器
- 误差特性评估方法
- 探索神经元的容错性(近似计算的损失函数的偏导)
- 卷积层的容错性高于FC;越接近输出层容错性越差
- 基于容错的位宽调整方法
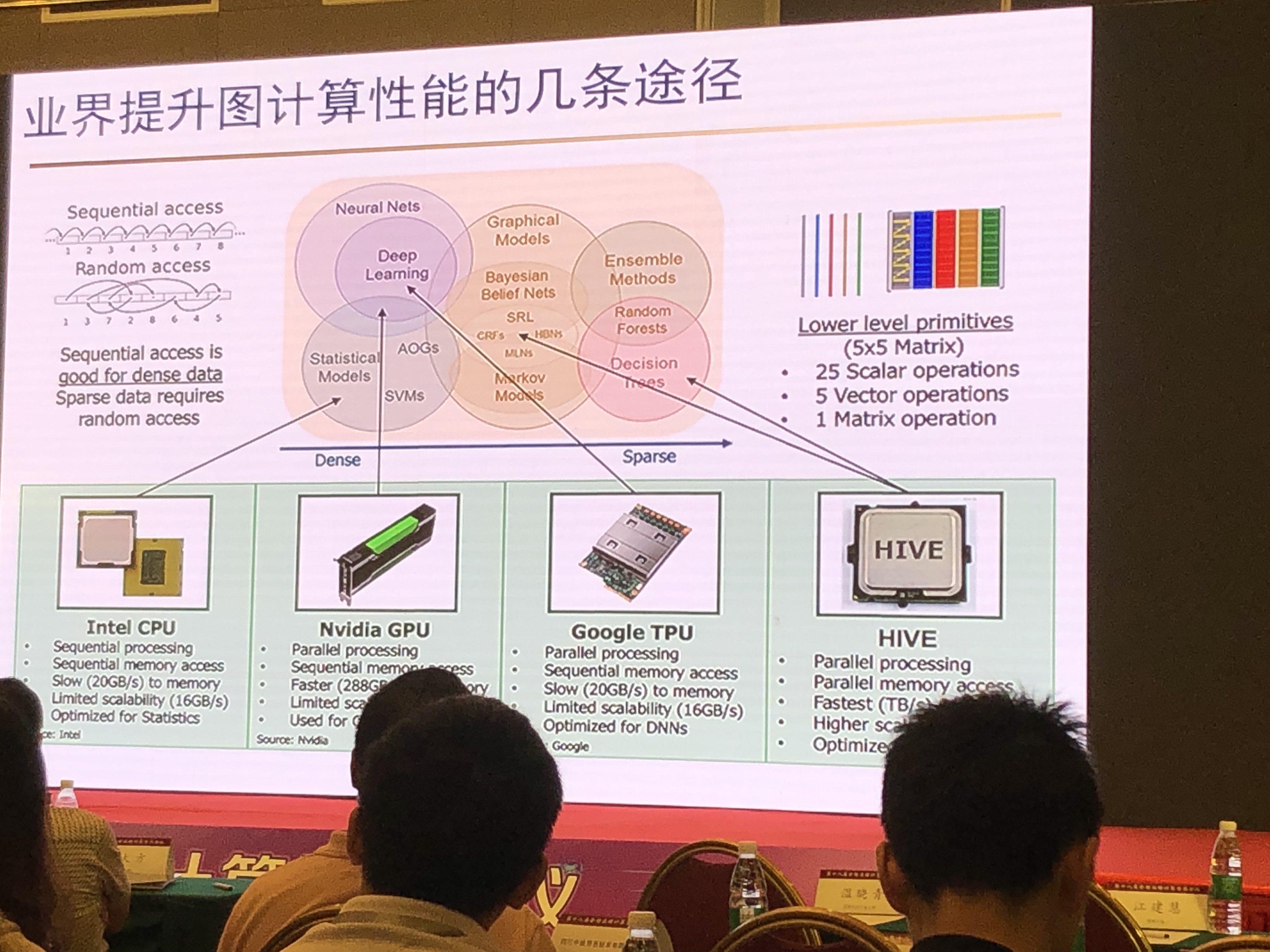
高效能图计算机设计的挑战与实践
金海 华中科技大学
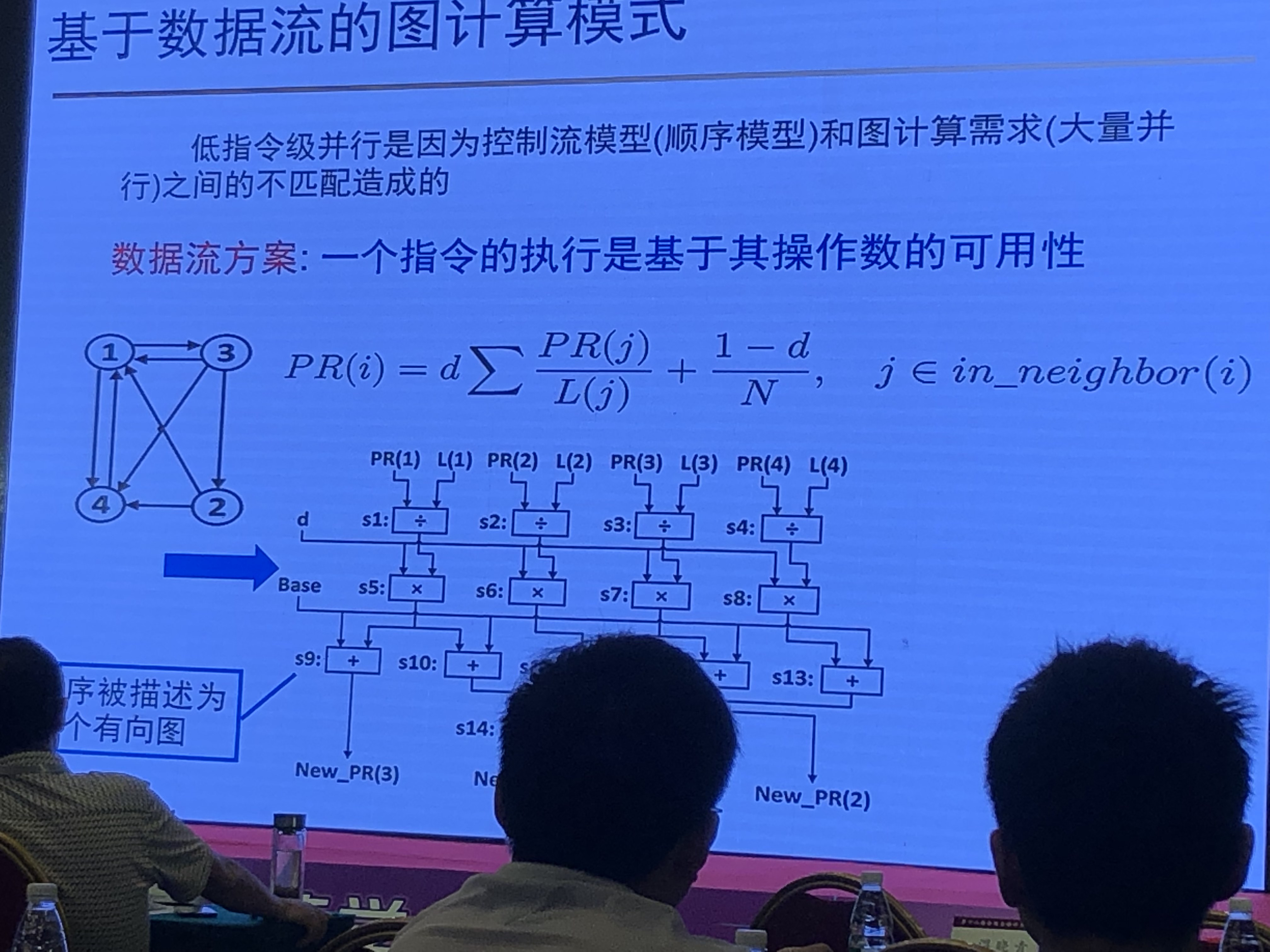
传统计算与图计算区别
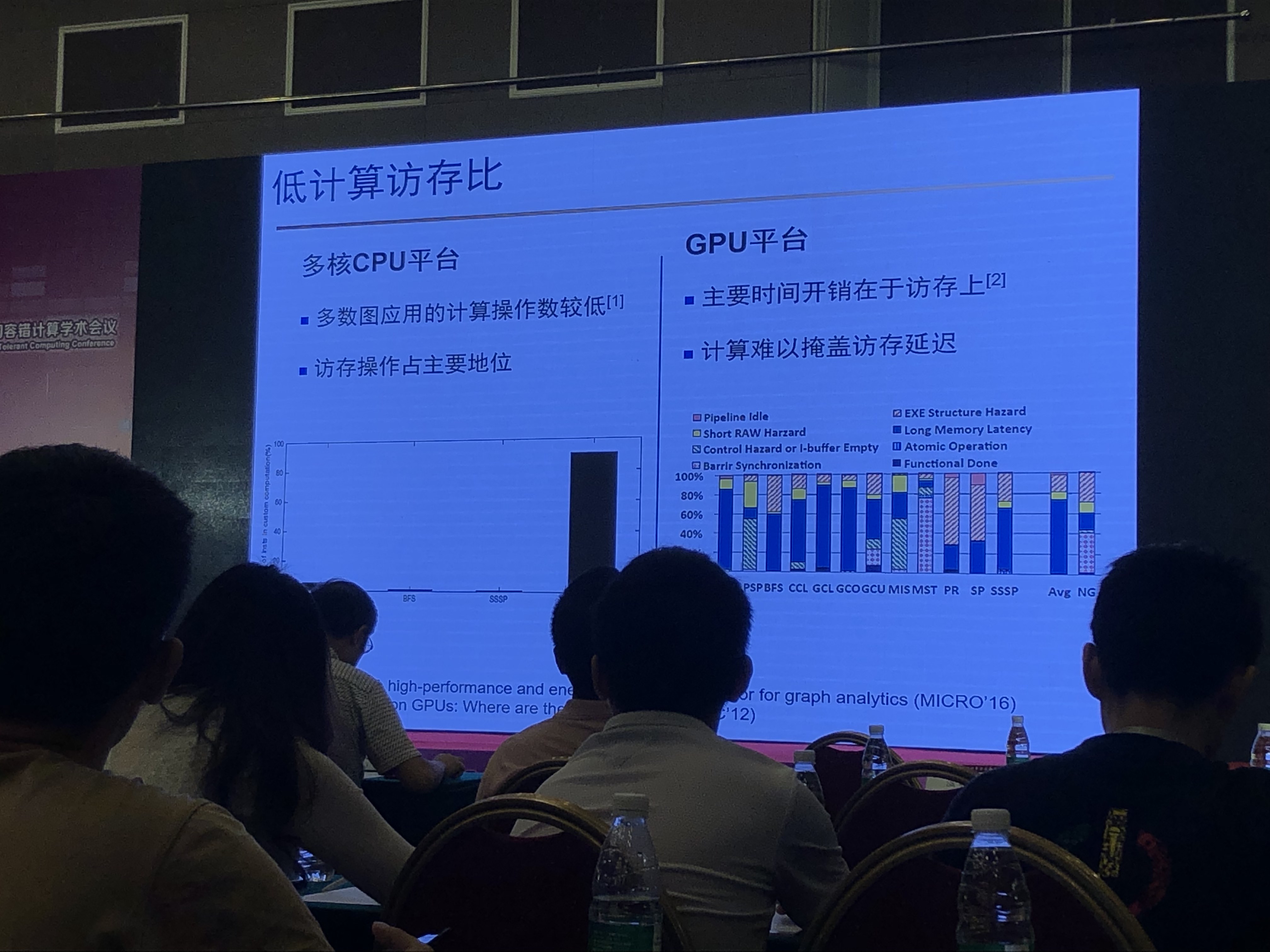
- 计算访存比高VS计算访存比低
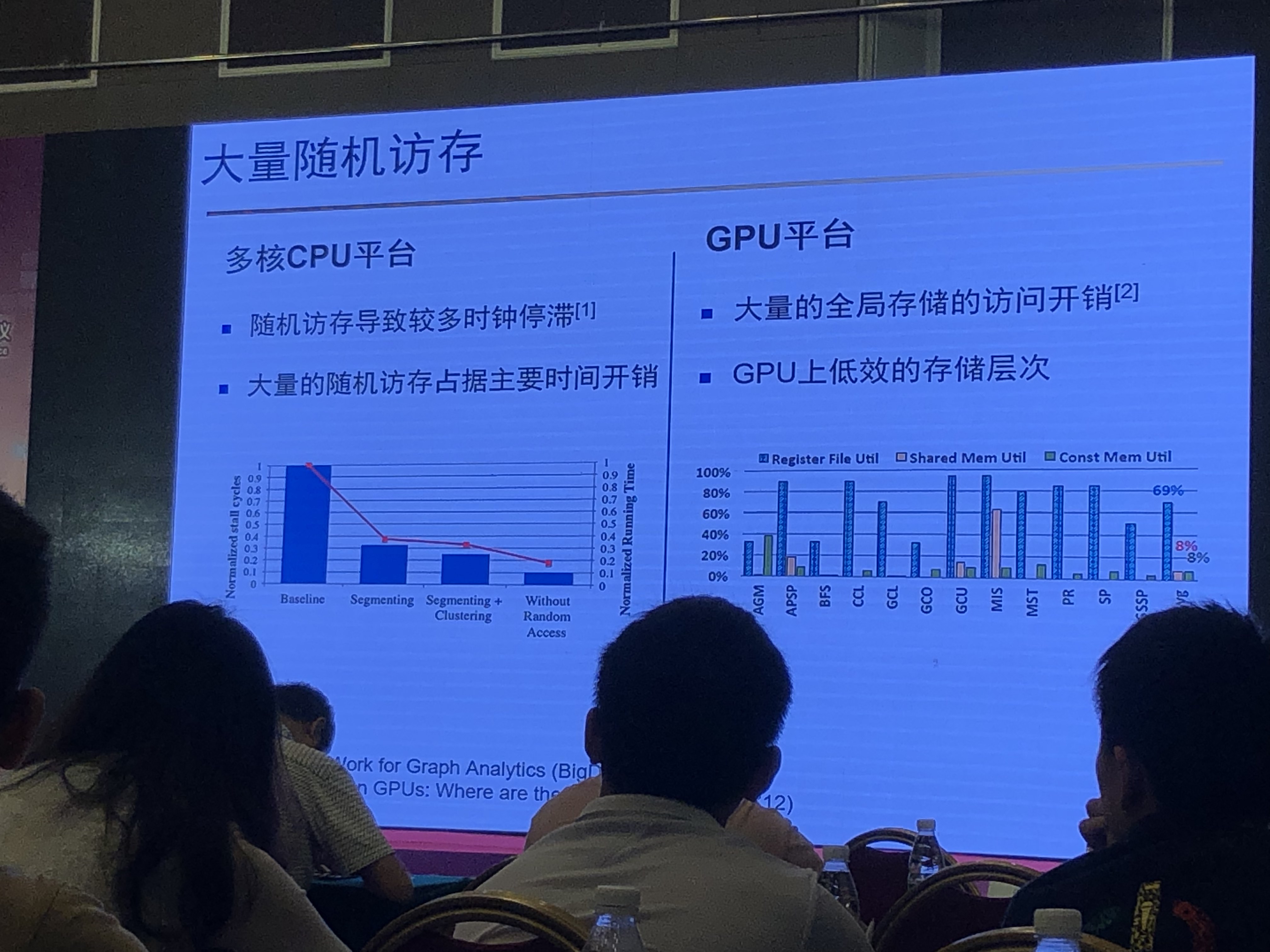
- 顺序访存VS随机访存
- 局部性好VS数据依赖性强
图计算挑战
- 计算访存比低,难以掩盖访存延迟
- 大量随机访存带来的高额开销
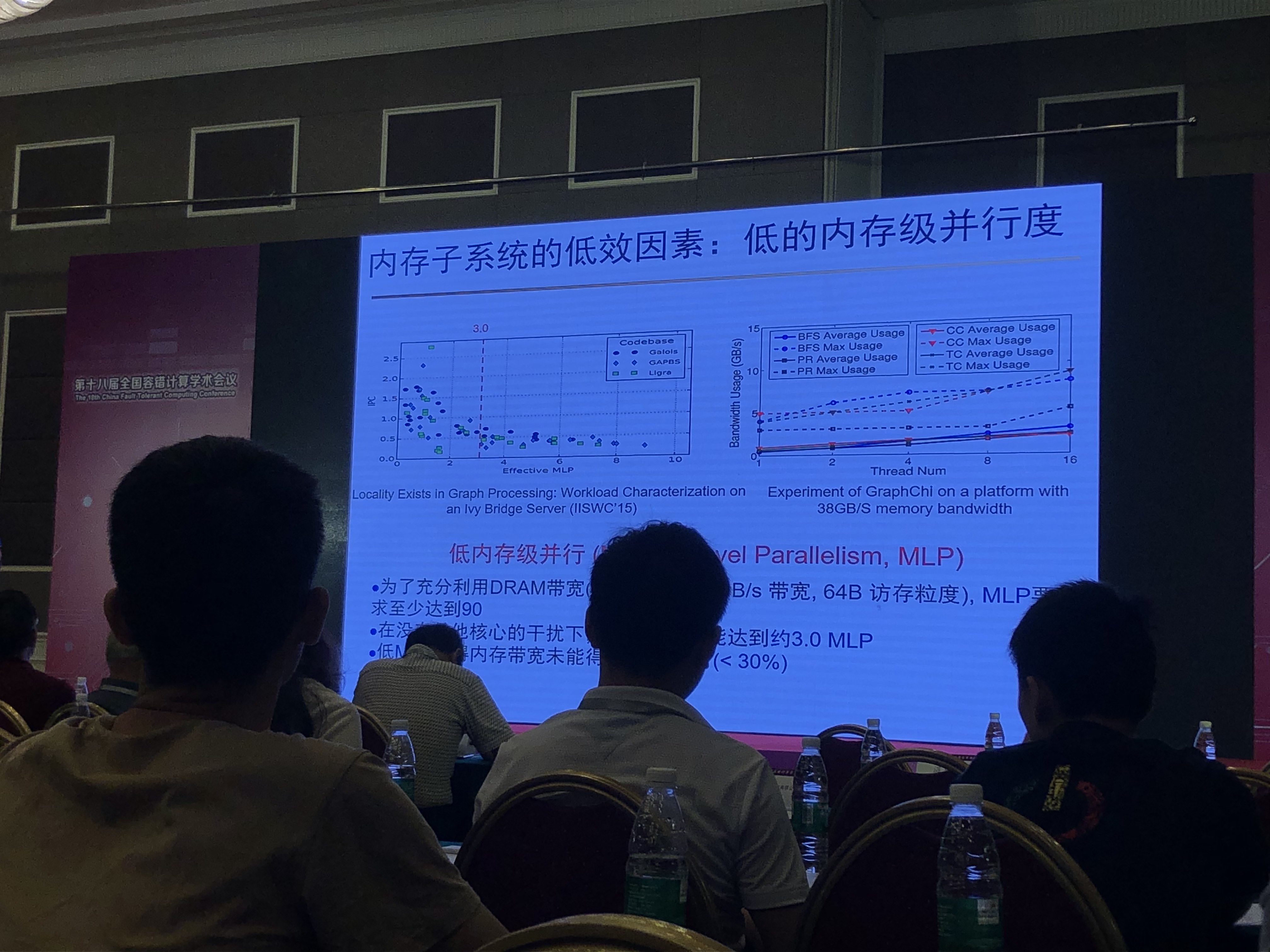
- 低效的缓存架构和内存并行度
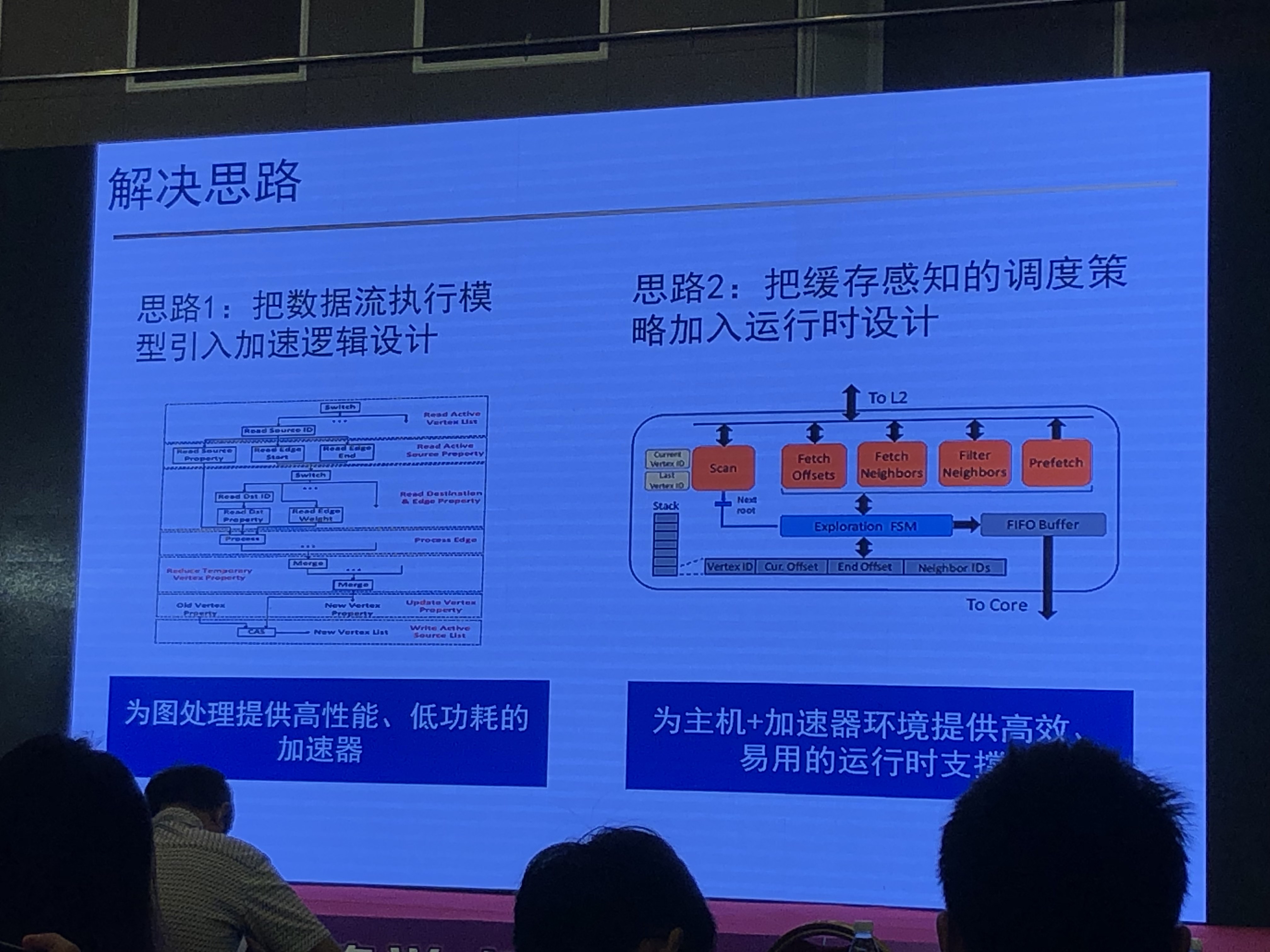
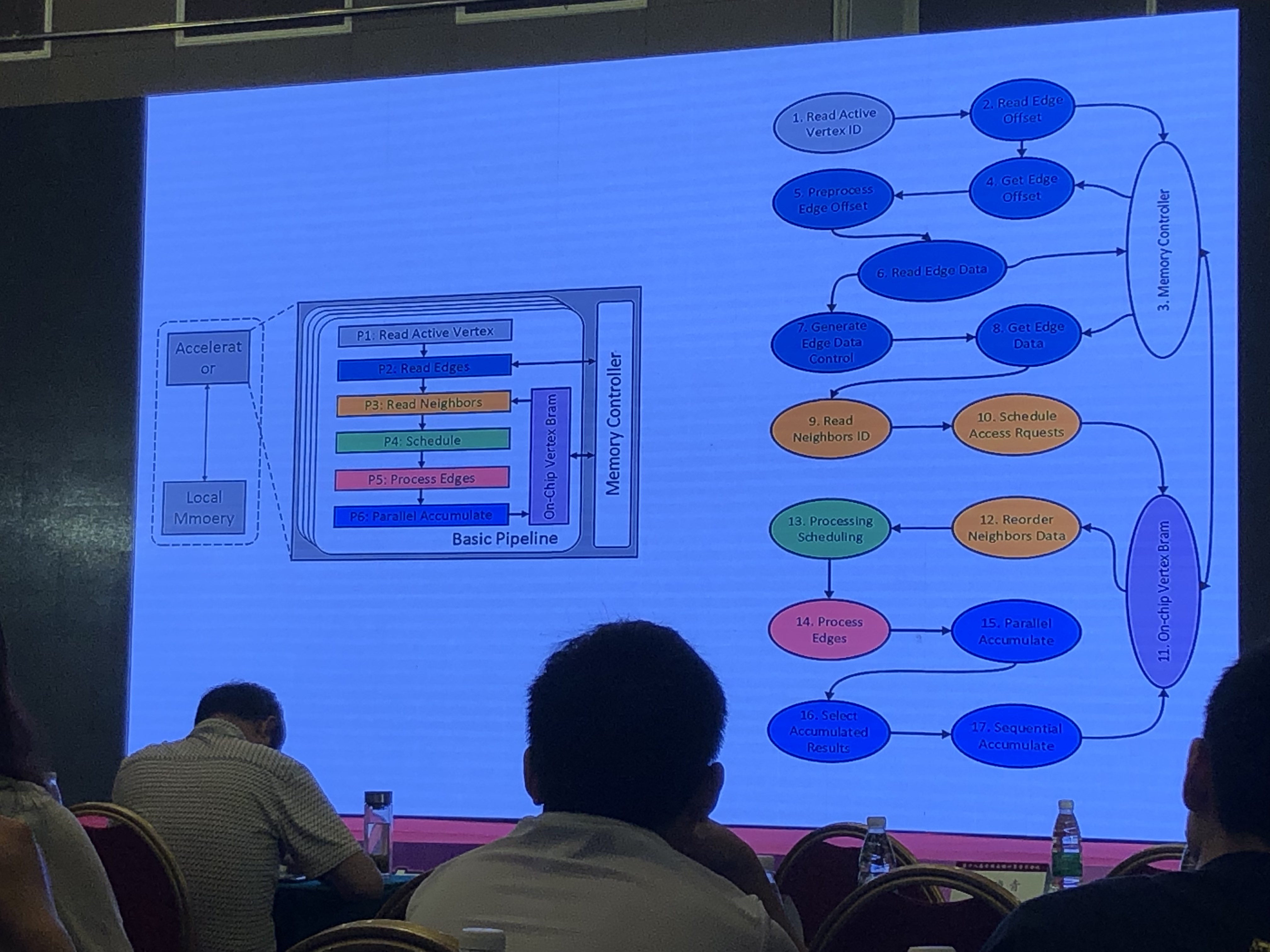
解决思路
- 计算逻辑层面:基于数据流的并行图计算模式
- 存储架构层面:缓存感知








云计算基础研究的可靠计算
- 陈义全 阿里云*
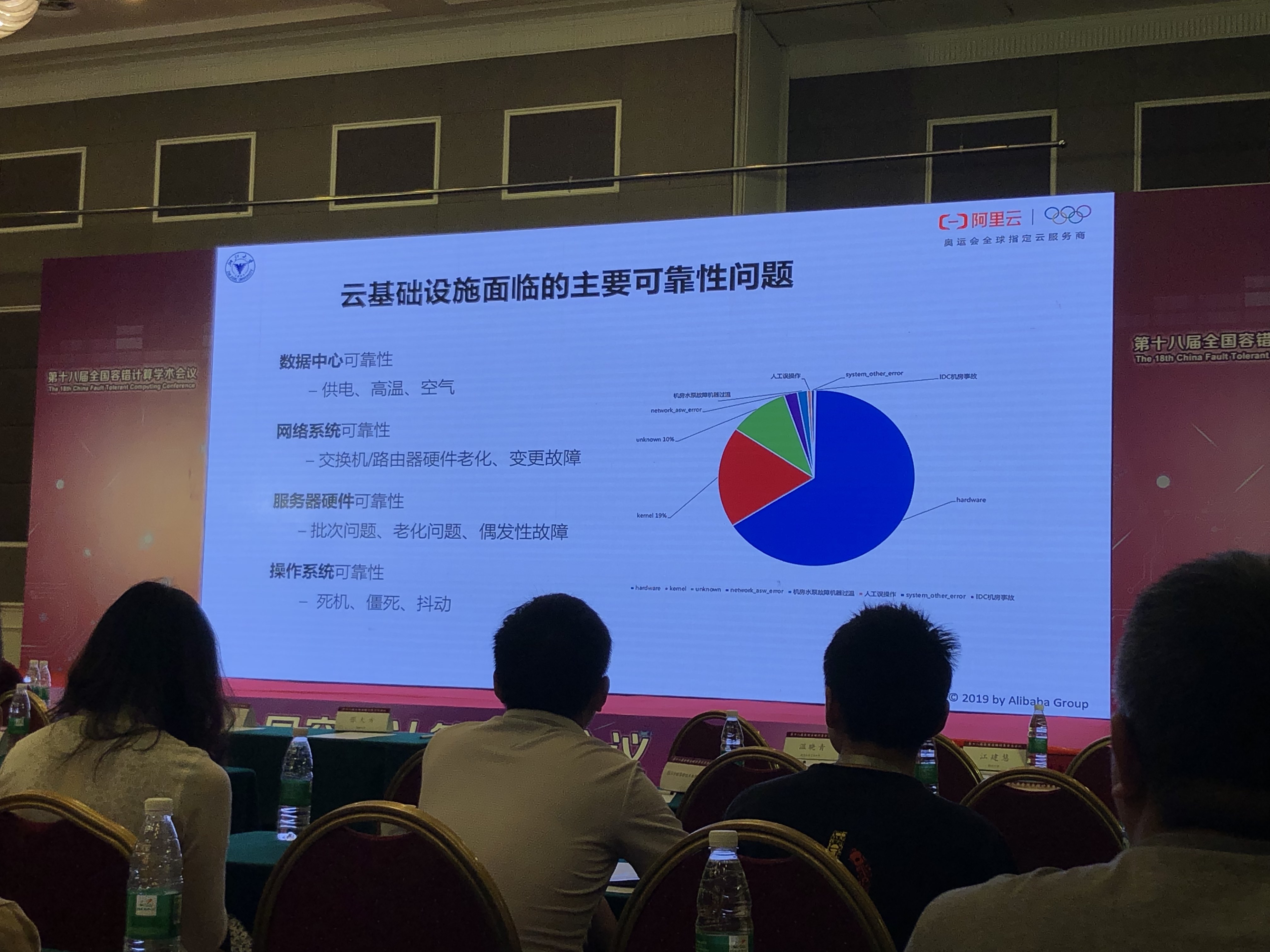
可靠性挑战
- 数据中心:供电、高温、空气
- 网络系统:交换机/路由器硬件老化、变更故障
- 服务器硬件:批次问题(不同设备供应商)、老化问题、偶发性故障
- 操作系统:死机、僵死、抖动
措施
- 服务器硬件: 拦截、诊断、监控、隔离、预测
- 网络系统:提前/快速发现、快速恢复、减少变更故障
- 数据中心:监控全覆盖、排除不可抗力
- 操作系统:差异化、精细化、缩小故障yu,提高Qos
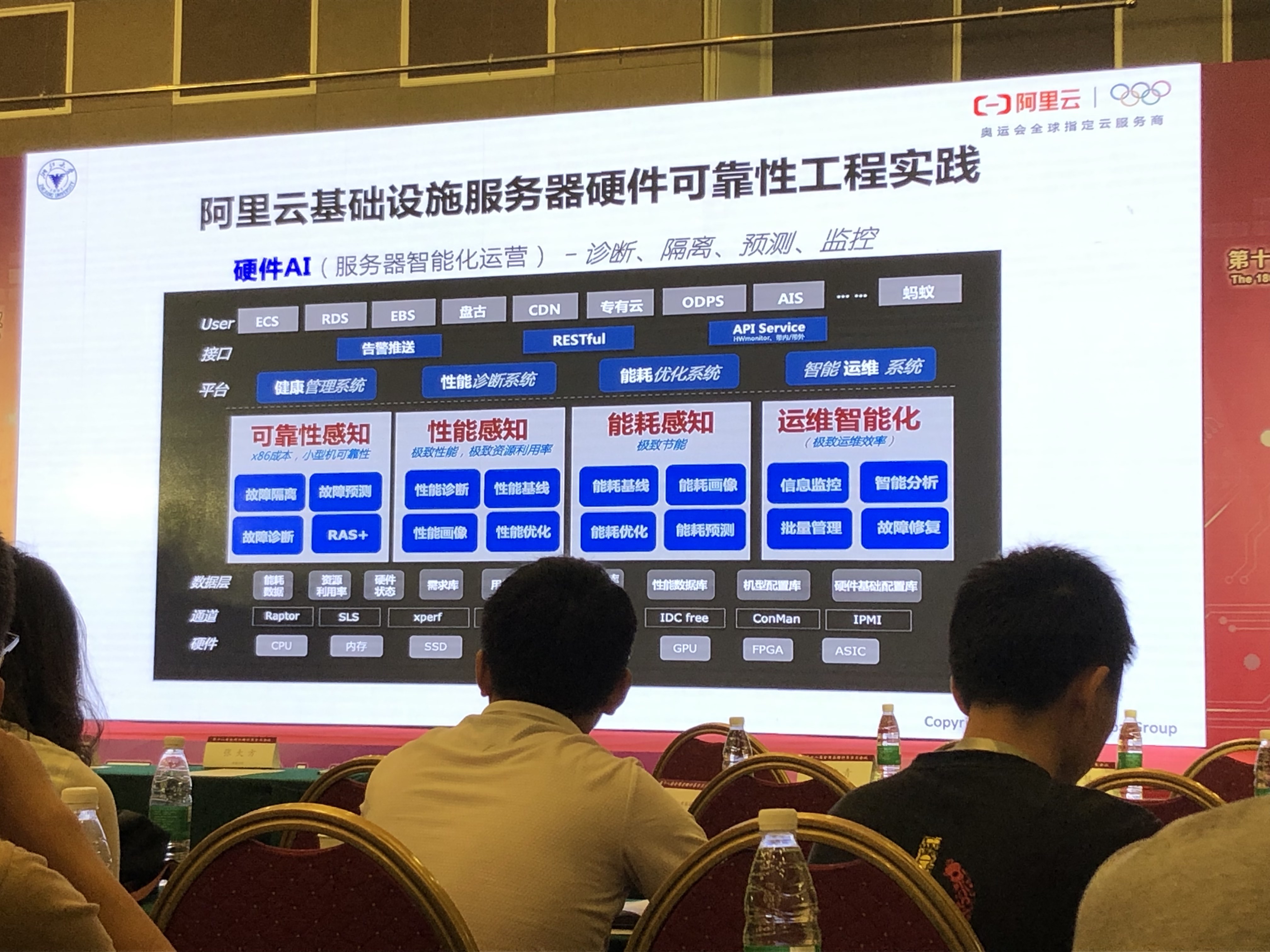
阿里云可靠性实践
- 硬件AI(服务器智能化运营):诊断、隔离、预测、监控
- 可靠性感知:故障隔离、预测、诊断、RAS+
- 性能感知:性能诊断、基线、画像、优化
- 能耗感知:能耗极限、画像、优化、预测
- 运维智能化:信息监控、智能分析、批量管理、故障恢复
- 金轮系统
- 巡洋舰系统





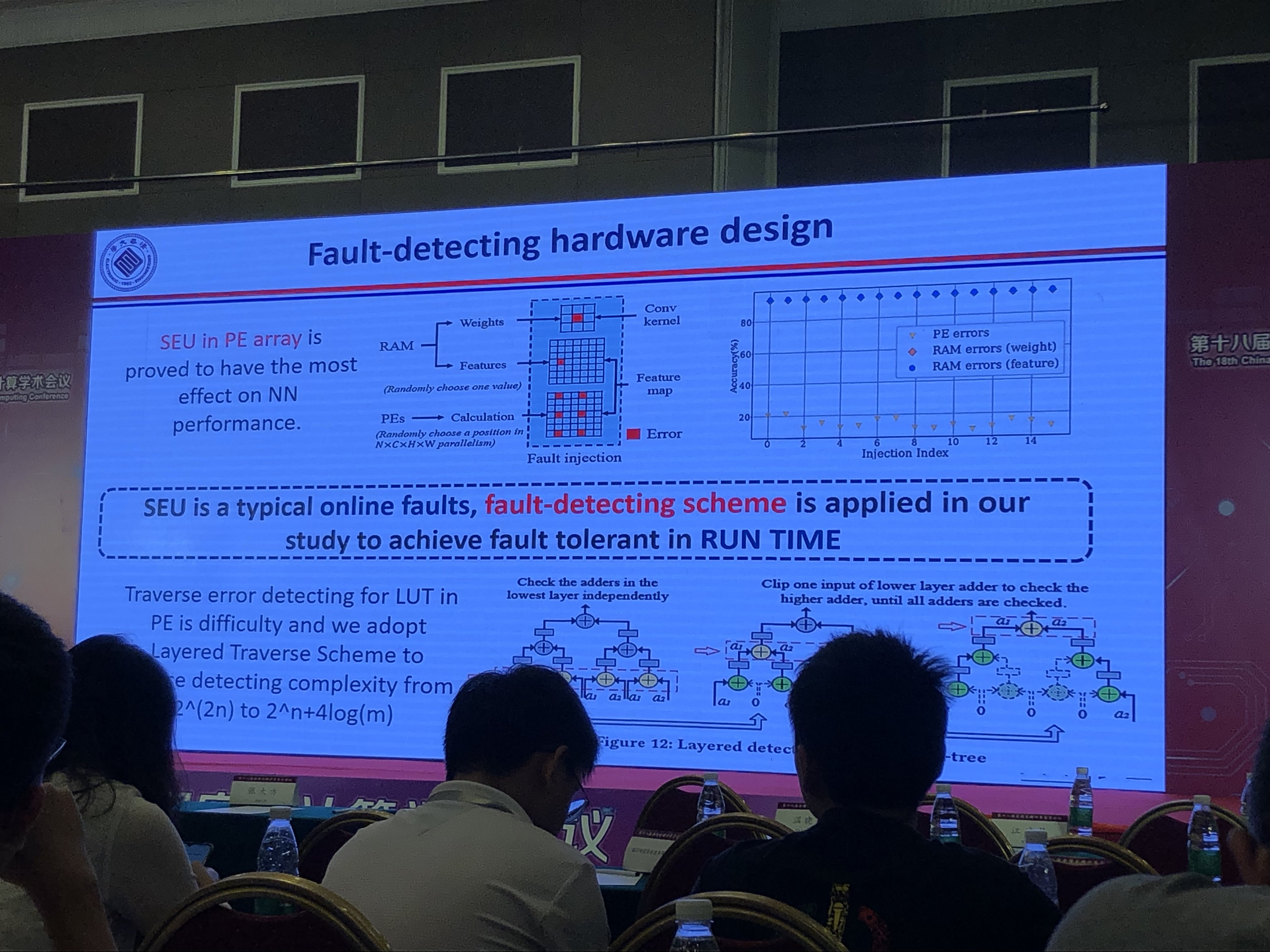
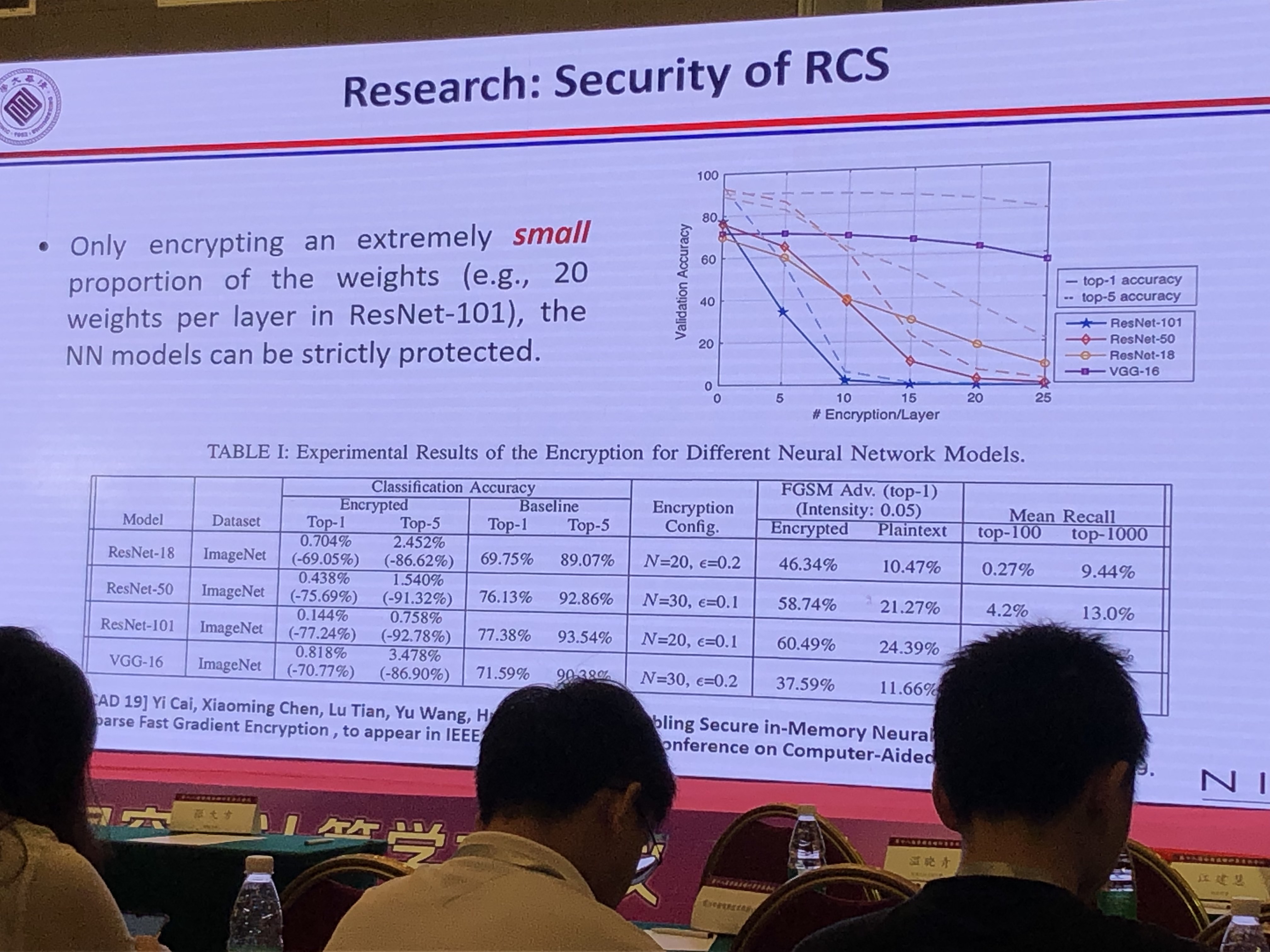
Fault Tolerant Neural Network Design for Hardware
- 汪玉 清华大学*
软硬件协同化设计:探索CNN节点的关键容错下;基于在线错误诊断的AI加速器
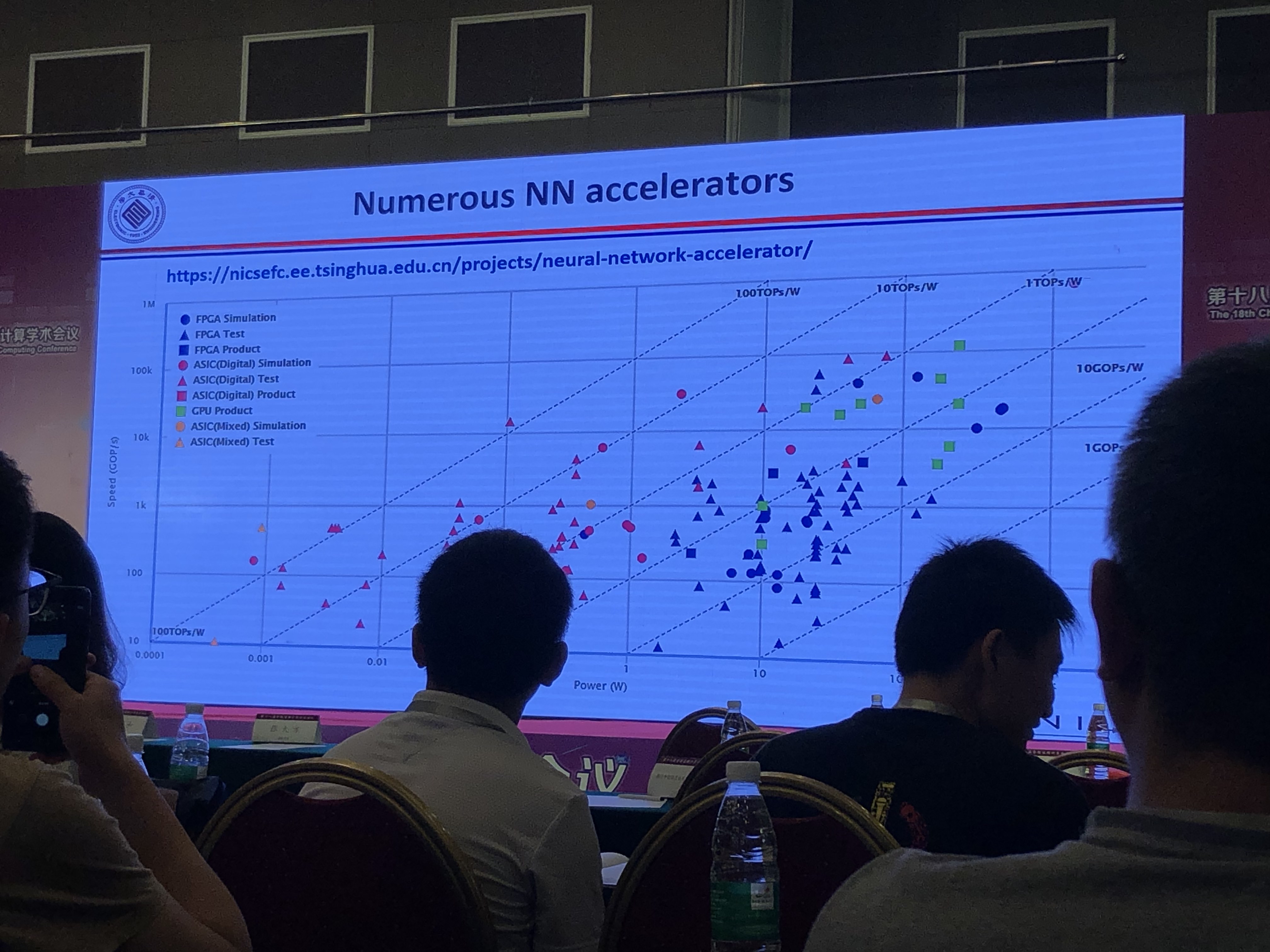
NN加速器的发展趋势
- 可参考清华研究组的统计
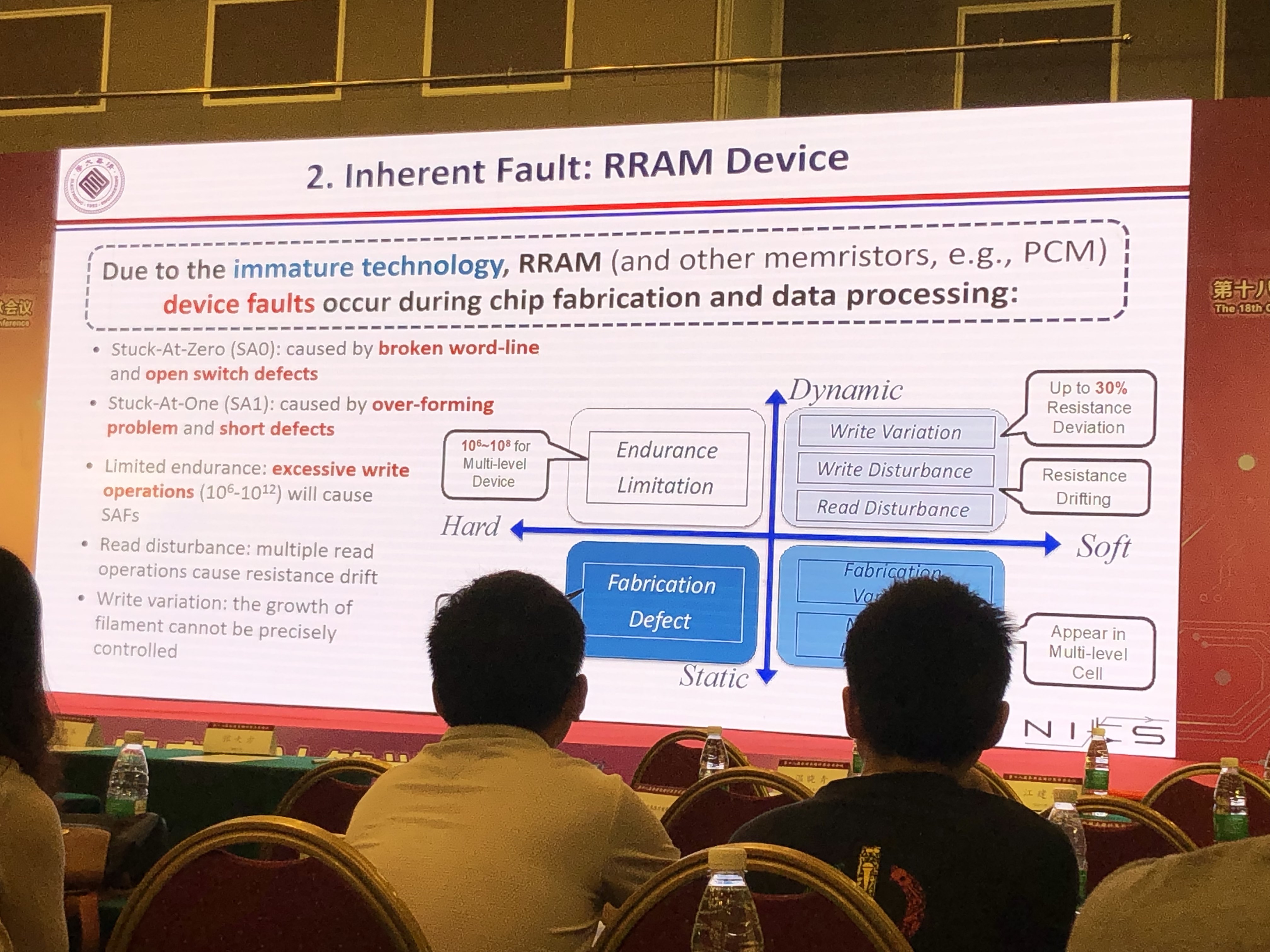
电路故障类型
- 环境影响:辐射、温度、供电
- 认为因素:安全攻击
- 内部错误:芯片制造,数据处理
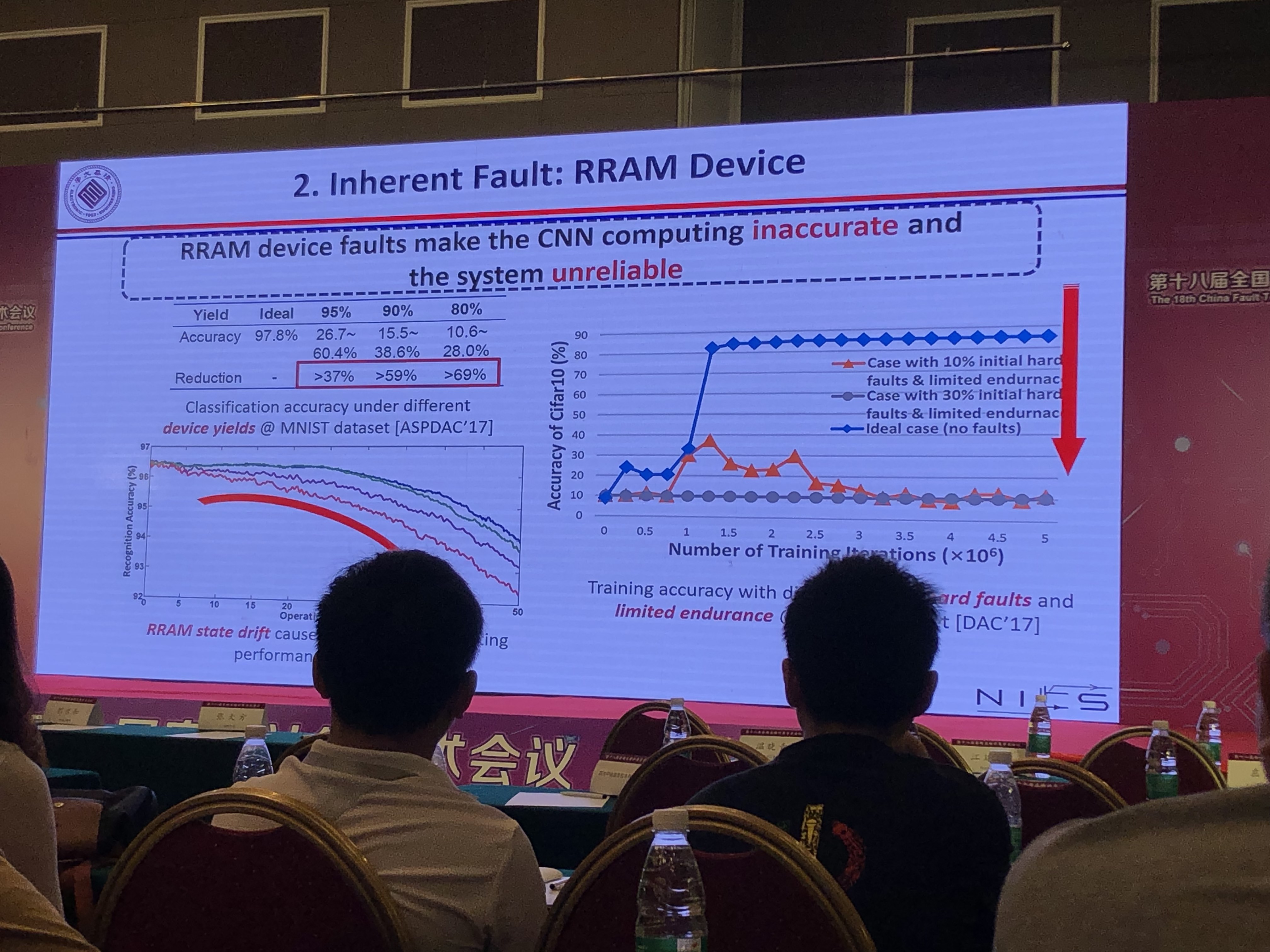
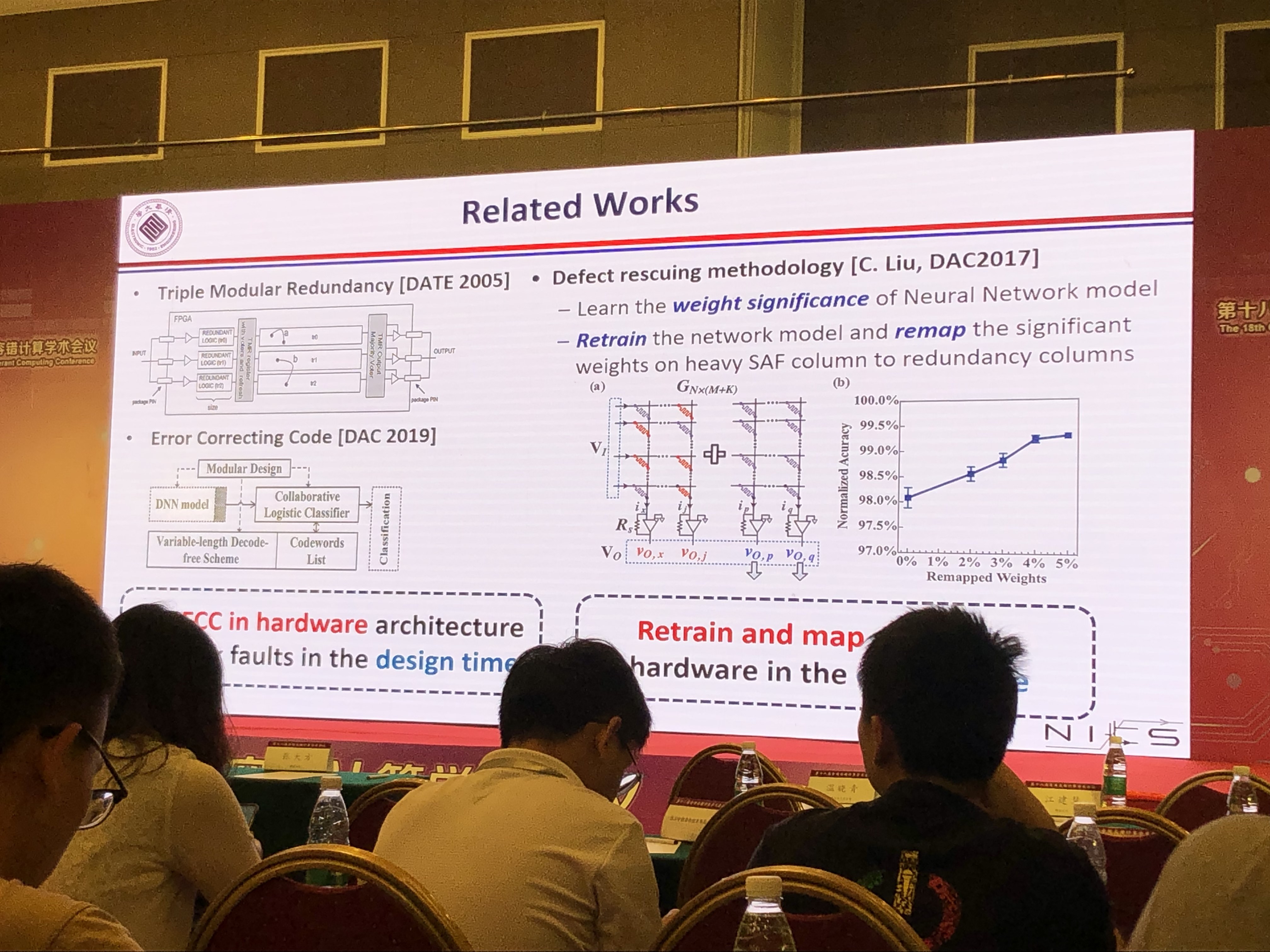
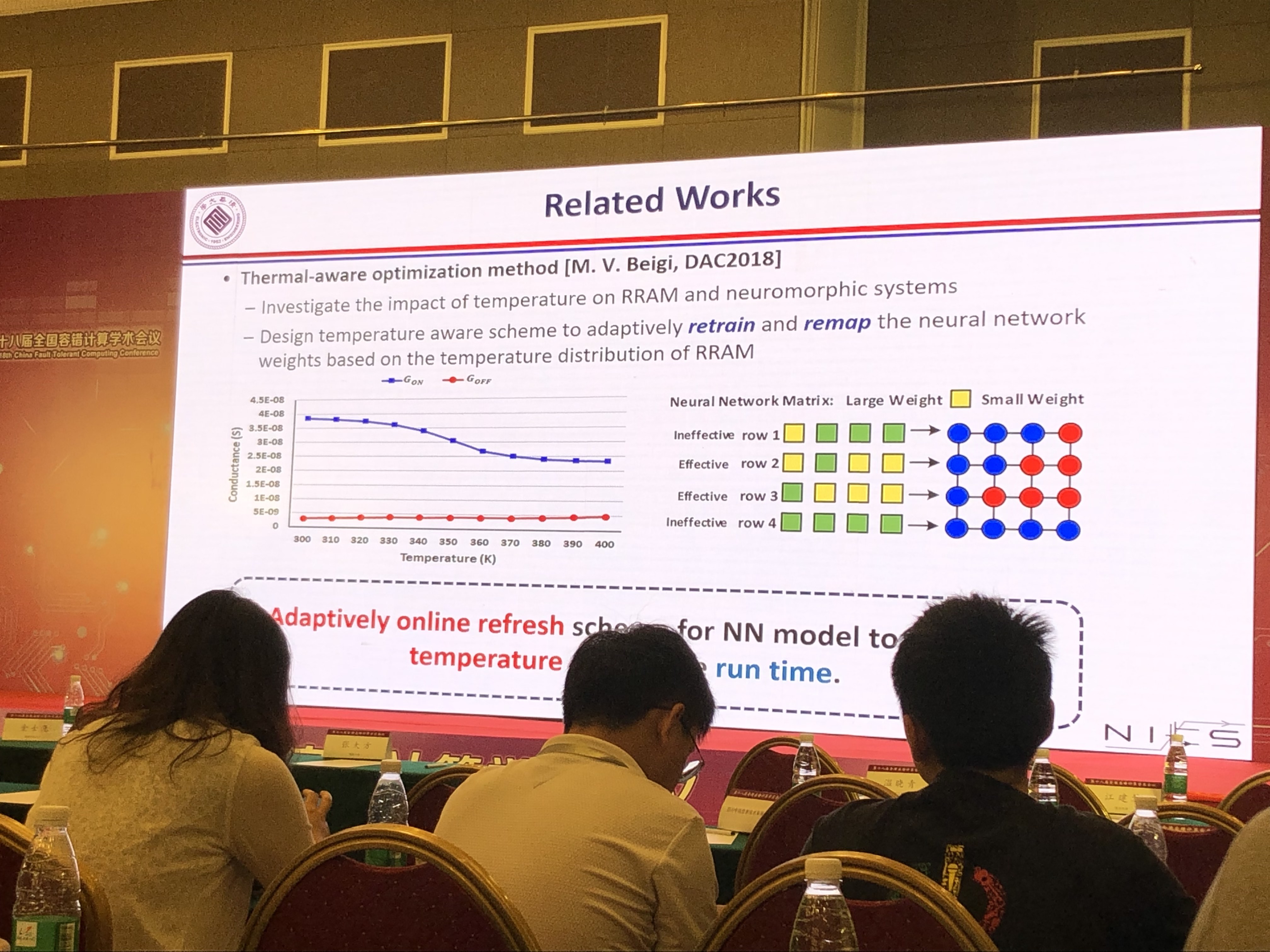
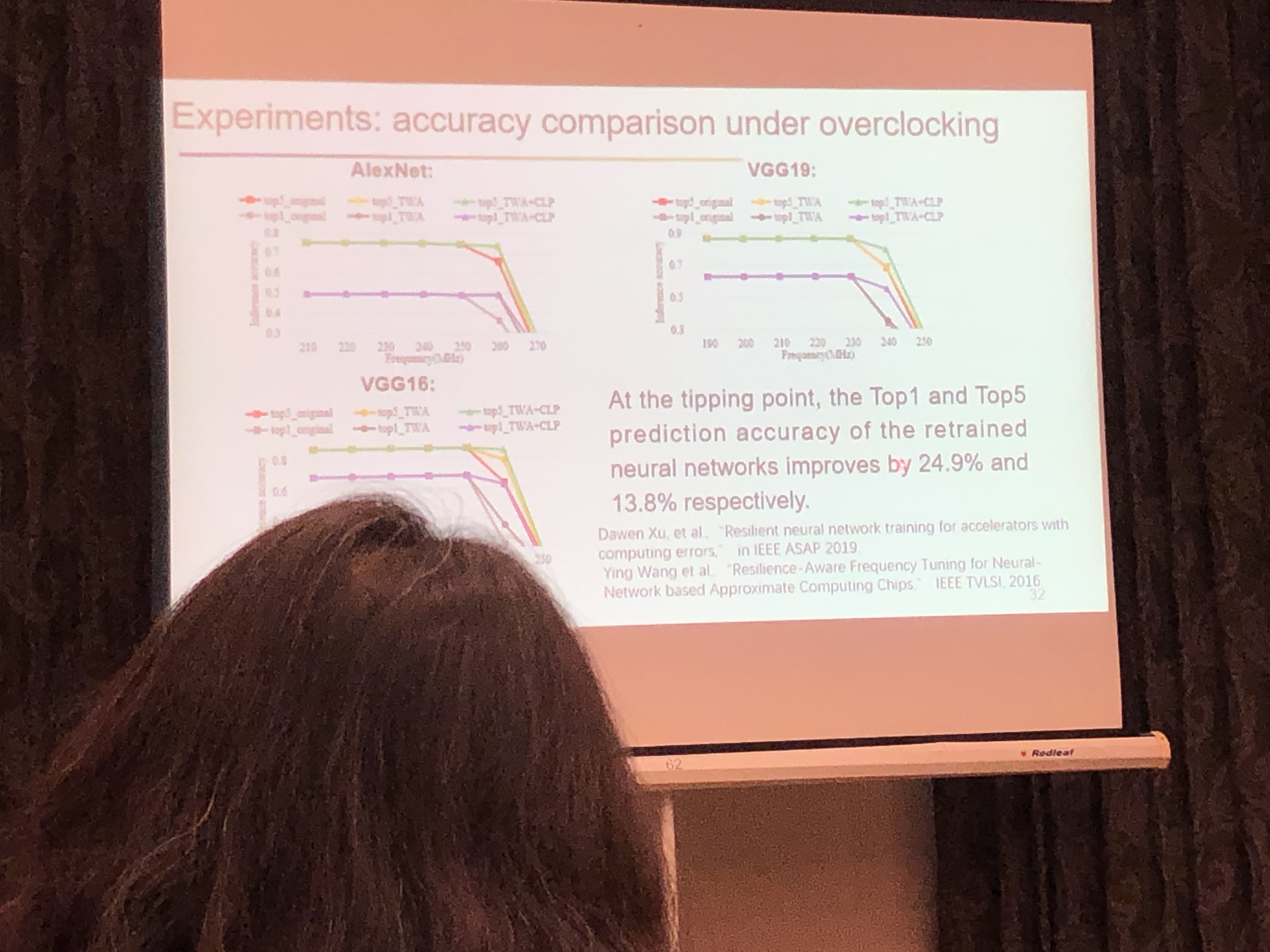
CNN容错分析
- BRAM错误使CNN计算精度下降37%~68%
- CNN容错关键点分析:CNN的某些节点有较好的容错性
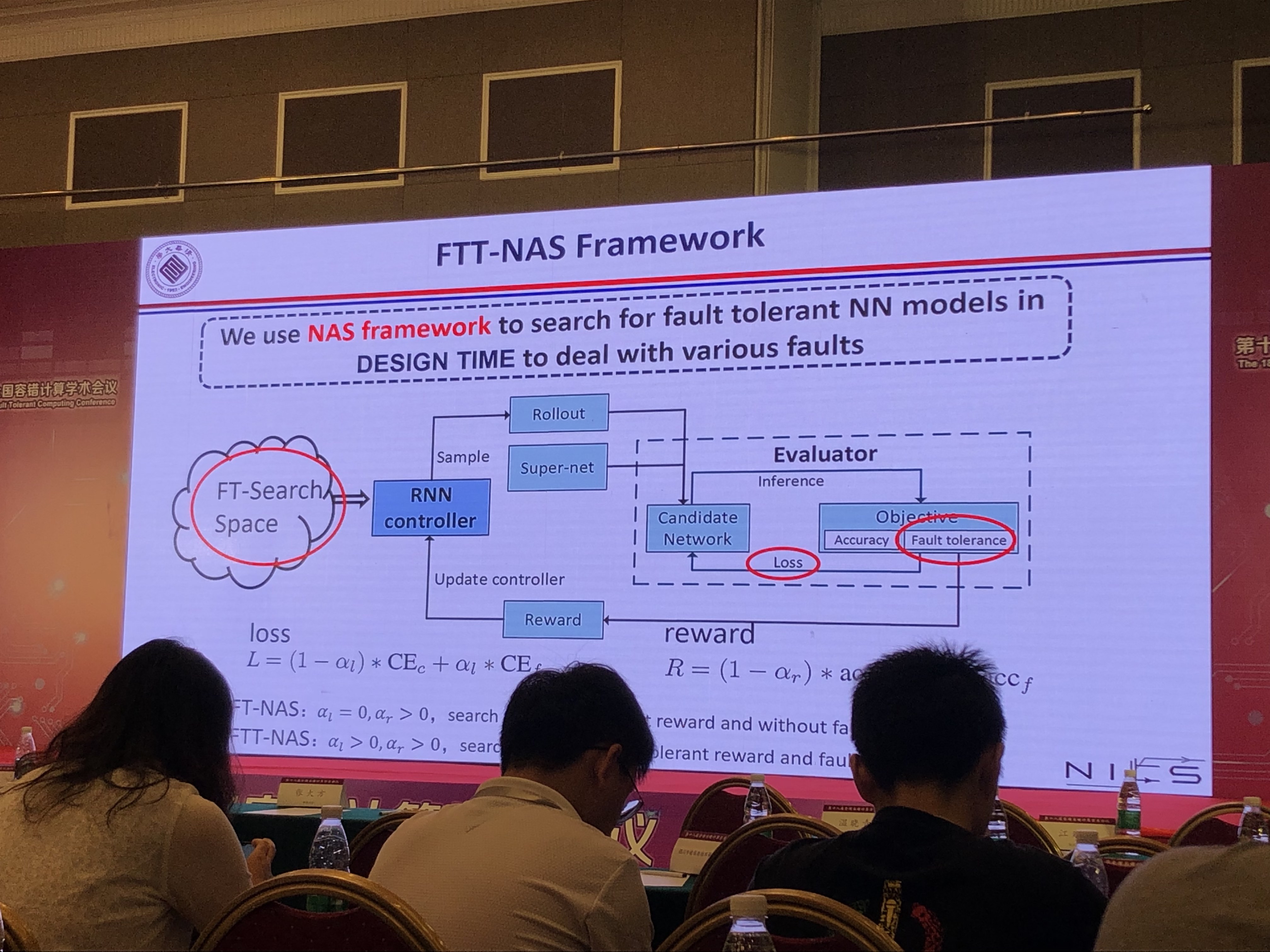
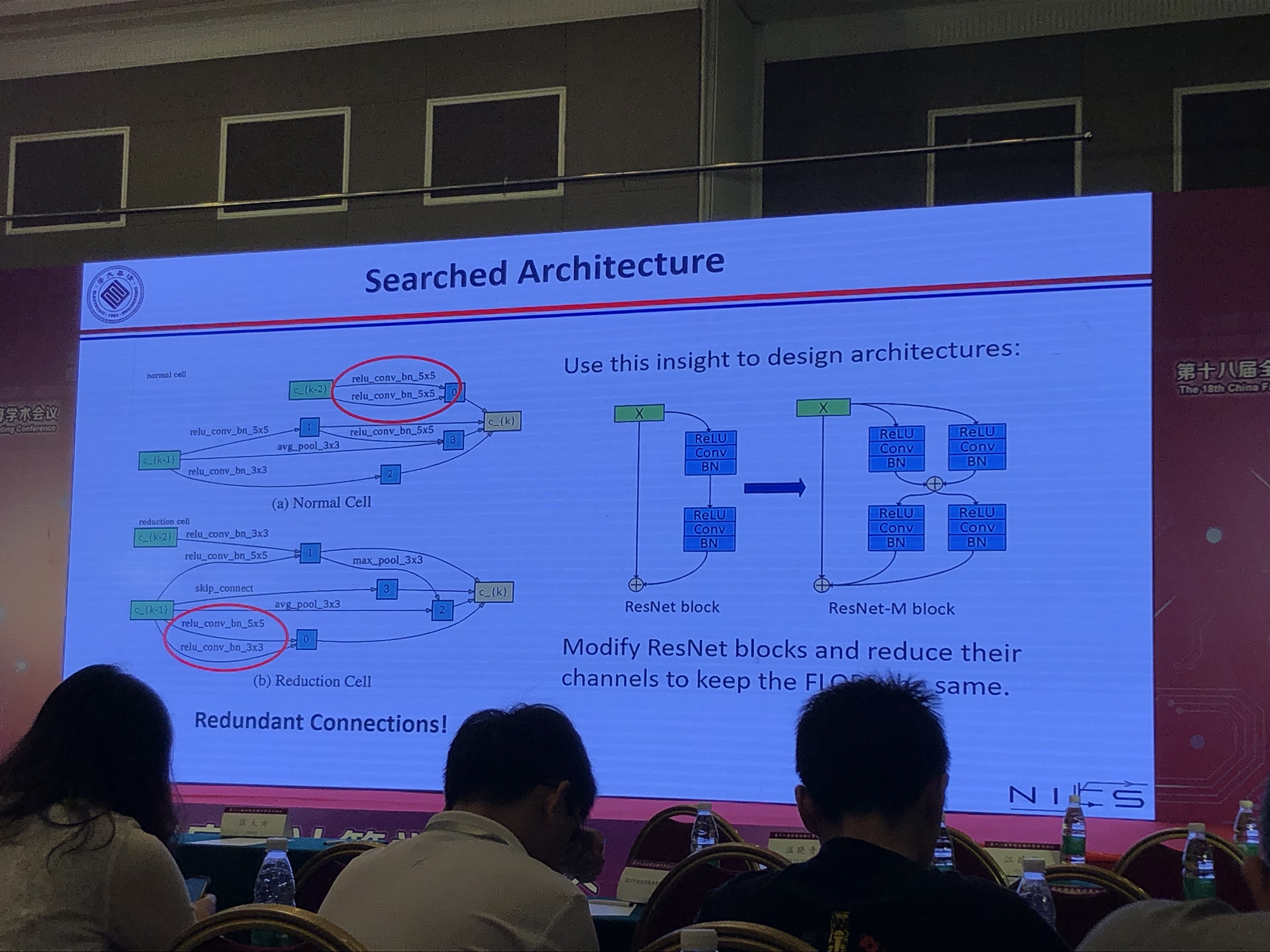
CNN芯片的容错设计
- 使用NAS框架探索/训练网络的容错节点,会改变网络结构
- 使用SEU运行时检测电路错误
- 实验效果:比起错误的CNN芯片减少了70%到80%的精度损失










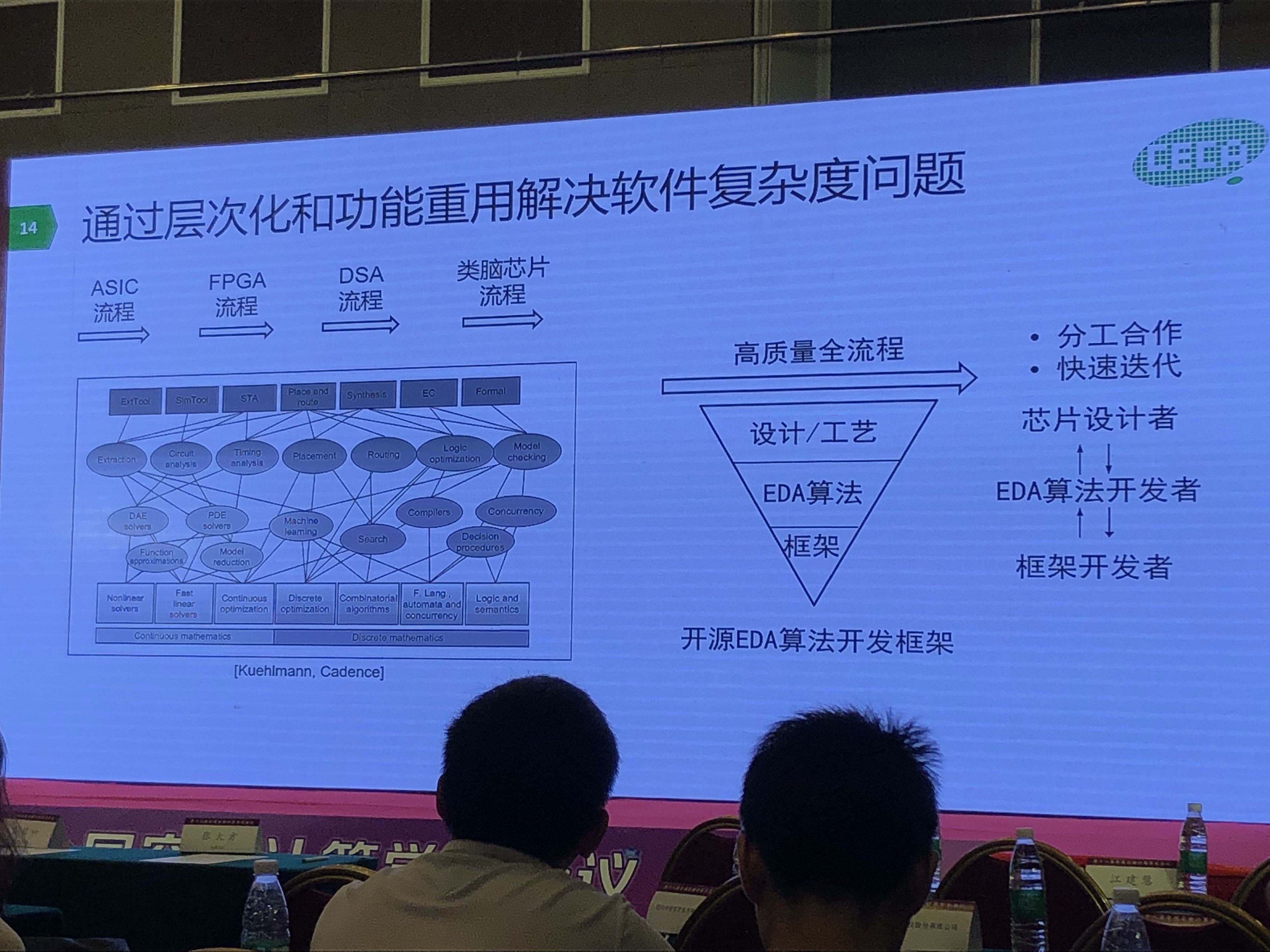
OpenBELT:开源EDA端到端框架的设想
罗国杰 北京大学
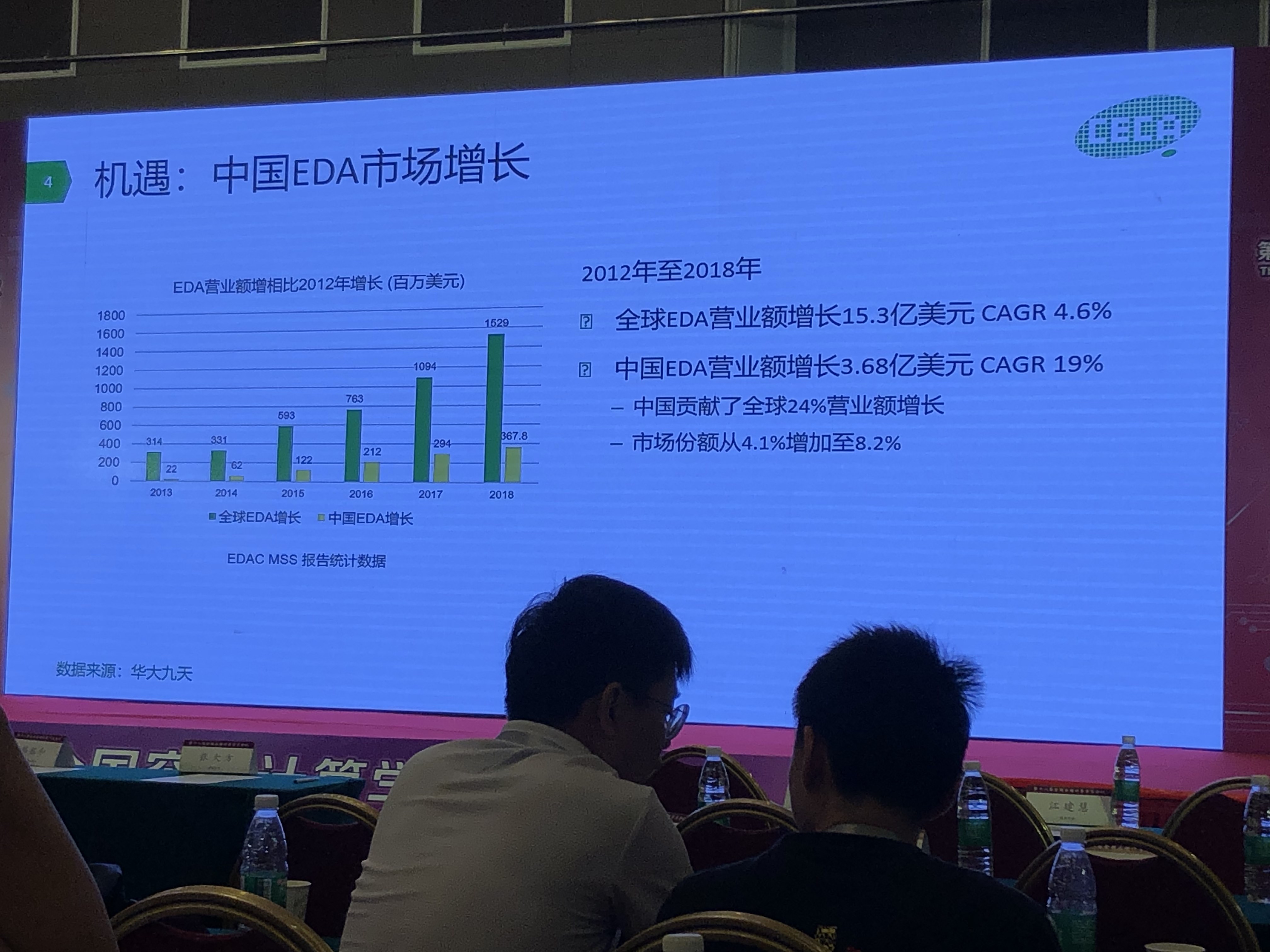
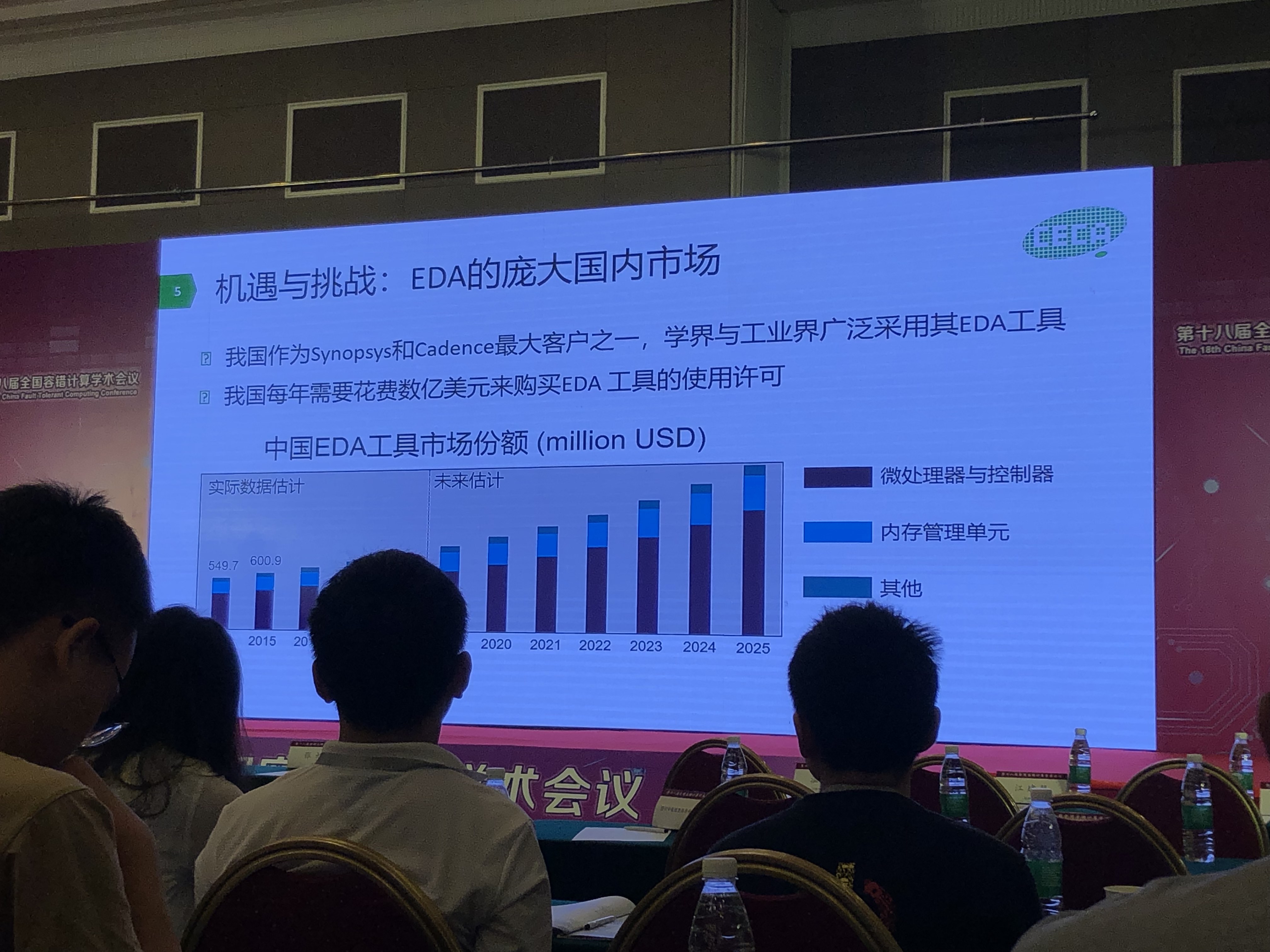
EDA机遇与挑战
- 依赖Synopsys与Cadence
- 国内市场庞大;增长强劲
开源EDA端到端工具链
- 规模化的教育培训
- 减少技术壁垒
- 降低研发成本与周期
- 层次化解决复杂的开发流程
国际开源EDA项目
- DATC
- OpenROAD
OpenBELT倡议
- 高效的算法和代码重用:算法/数据结构和执行/实现的解耦合
- 版本管理
- 分布式支持






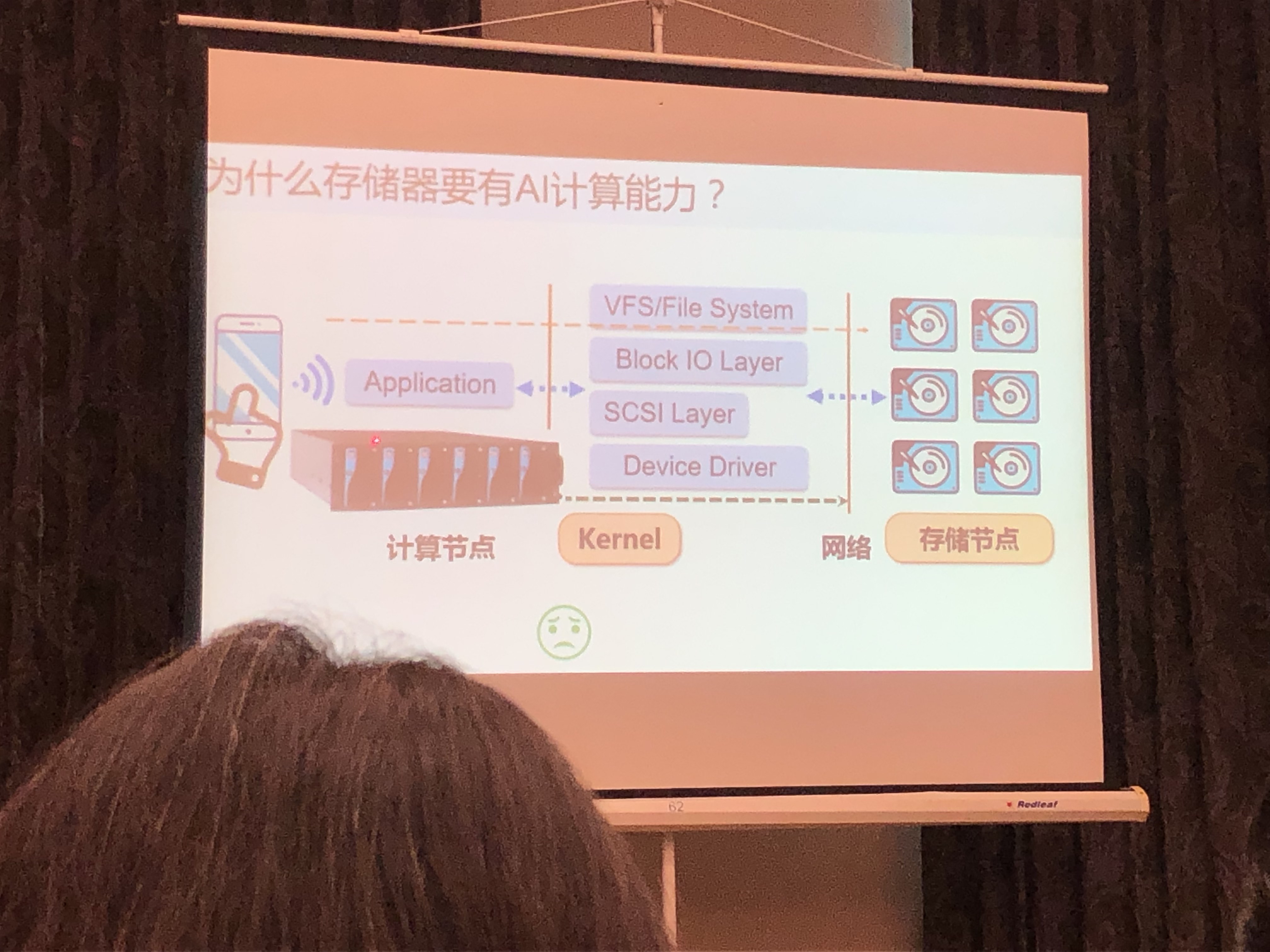
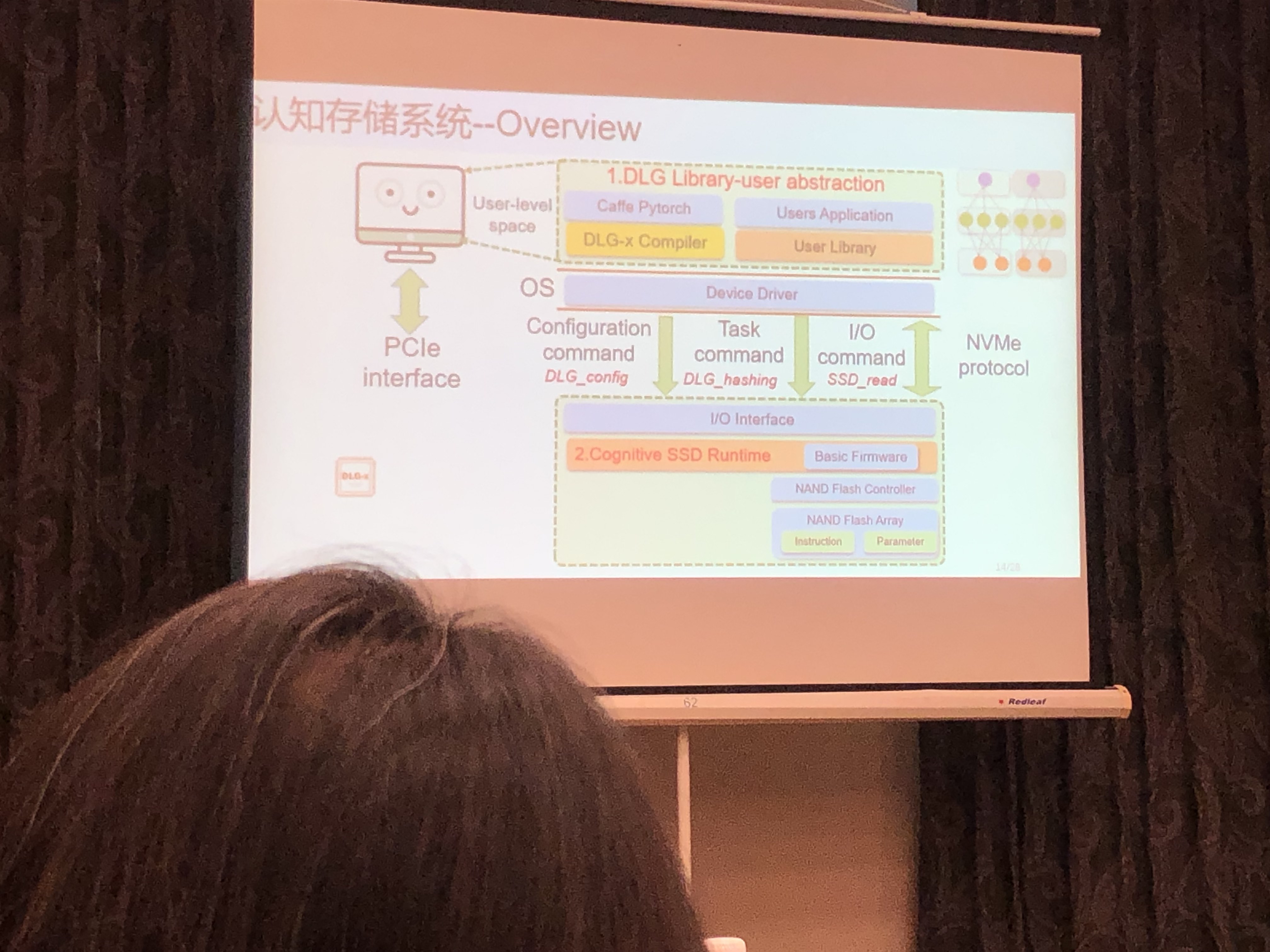
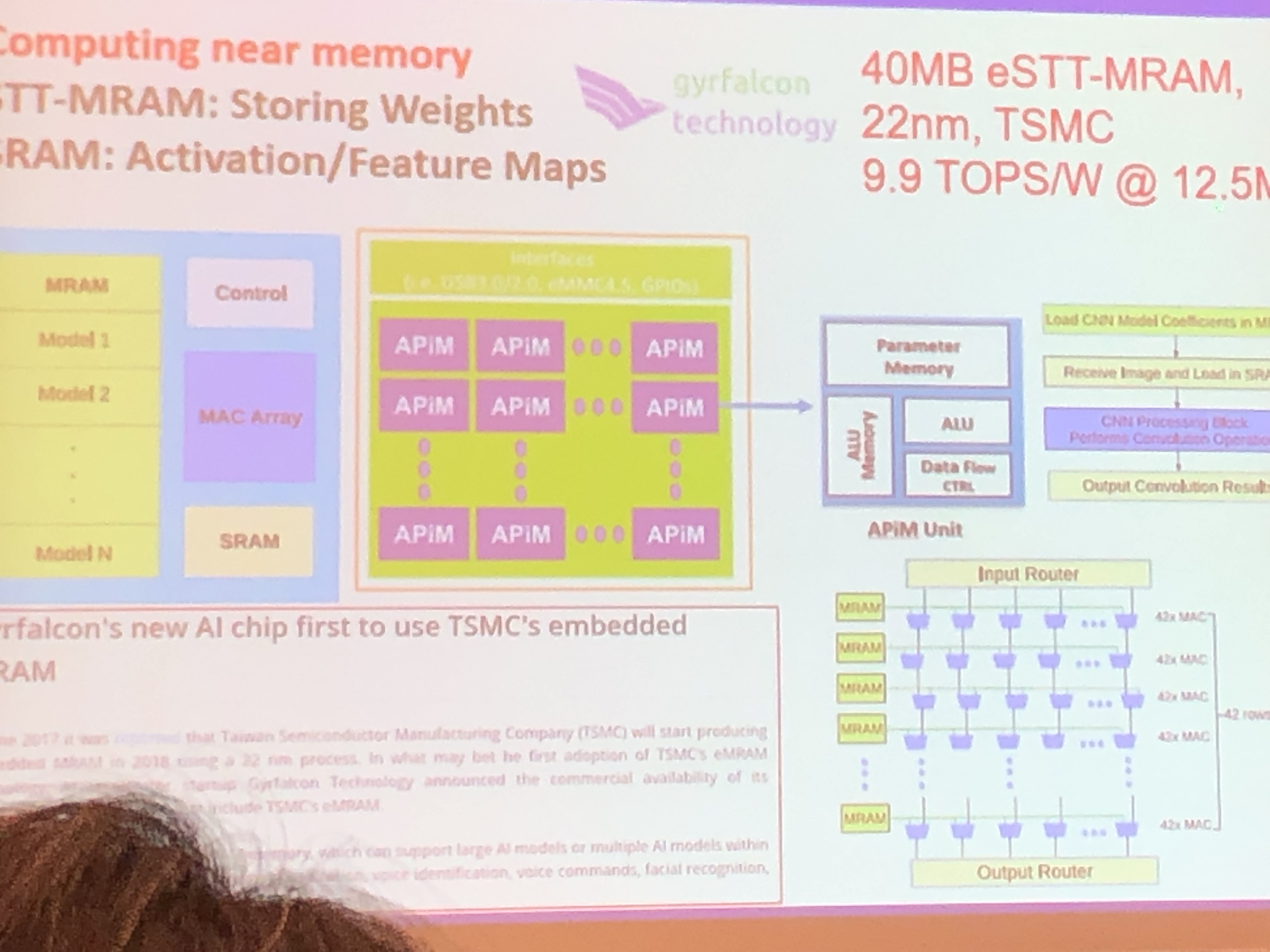
认知存储器(Cognitive SSD):一种基于SSD的近数据AI计算新引擎
王颖,中科院计算所
在SSD旁边嵌入专用计算引擎,实现AI感知与图搜索;消除非结构化数据带来的高额访存开销;在OpenSSD开发板上实现37X的CPU加速比。
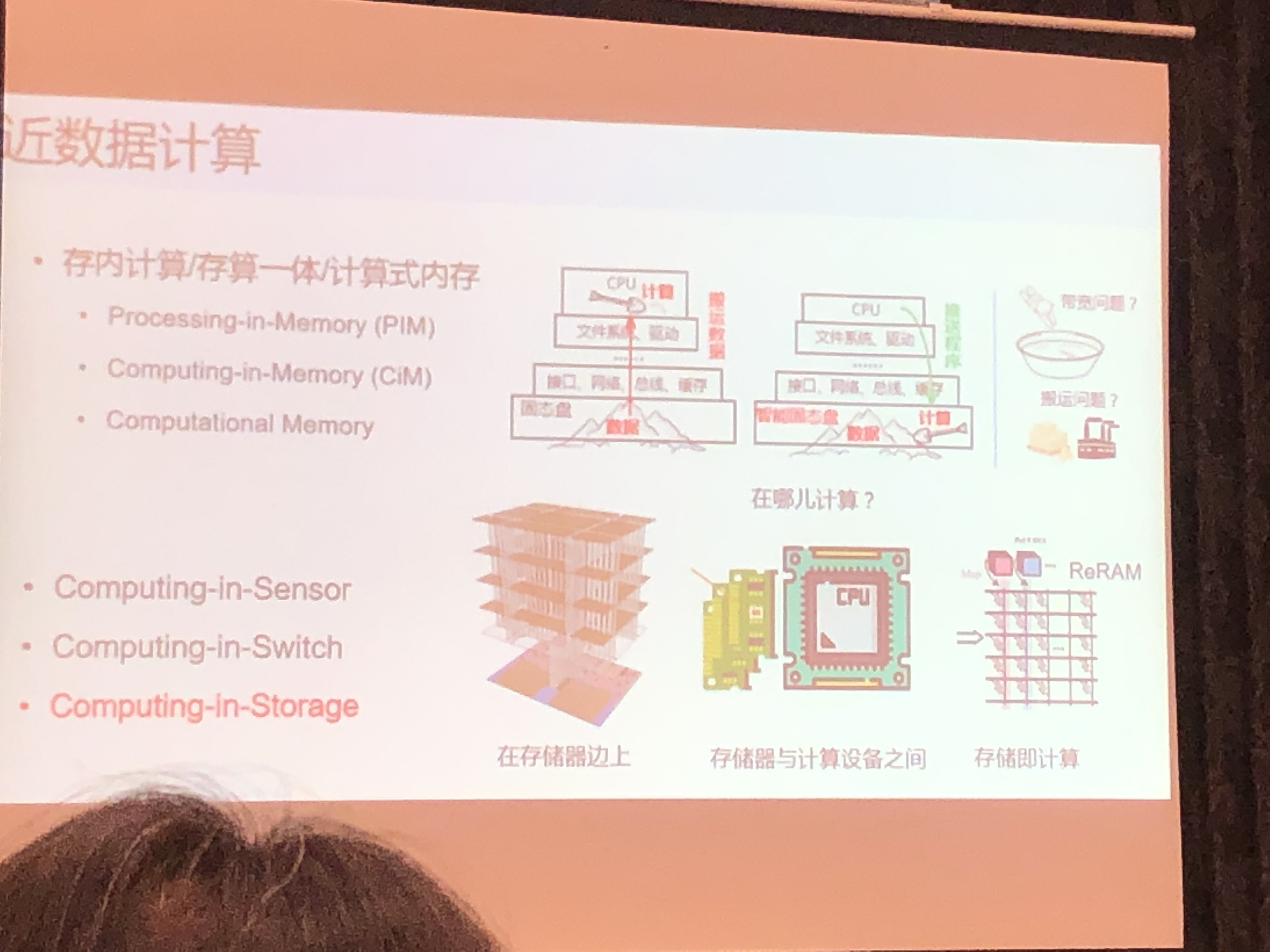
近数据计算(Near Data Processing)
- 存算一体化
- Processing-in-Memory (PIM)
- Computing-in-Memory (CIM)
- Computational Memory
- Computing-in-Sensor
- Computing-in-Switch
- Computing-in-Storage
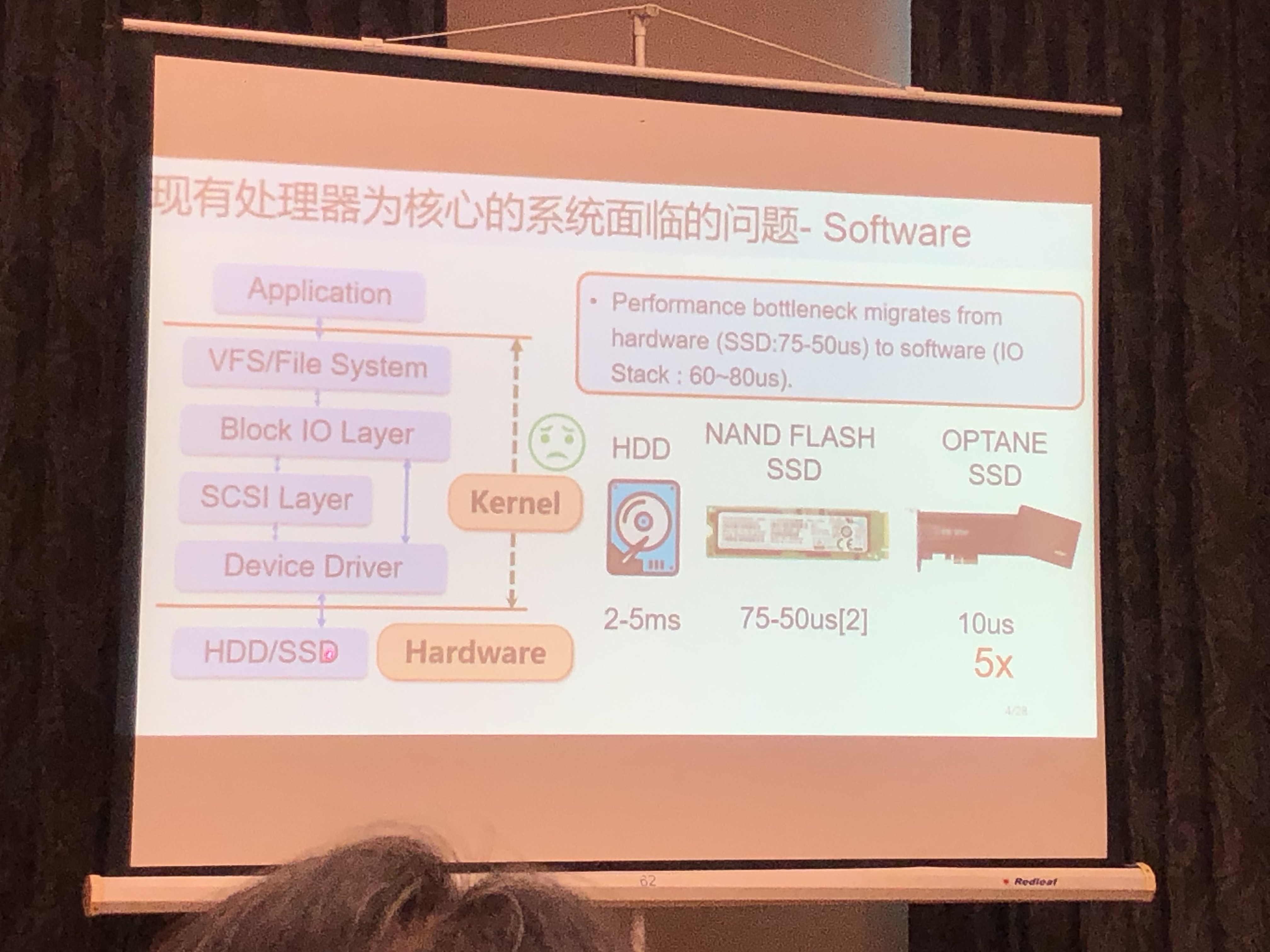
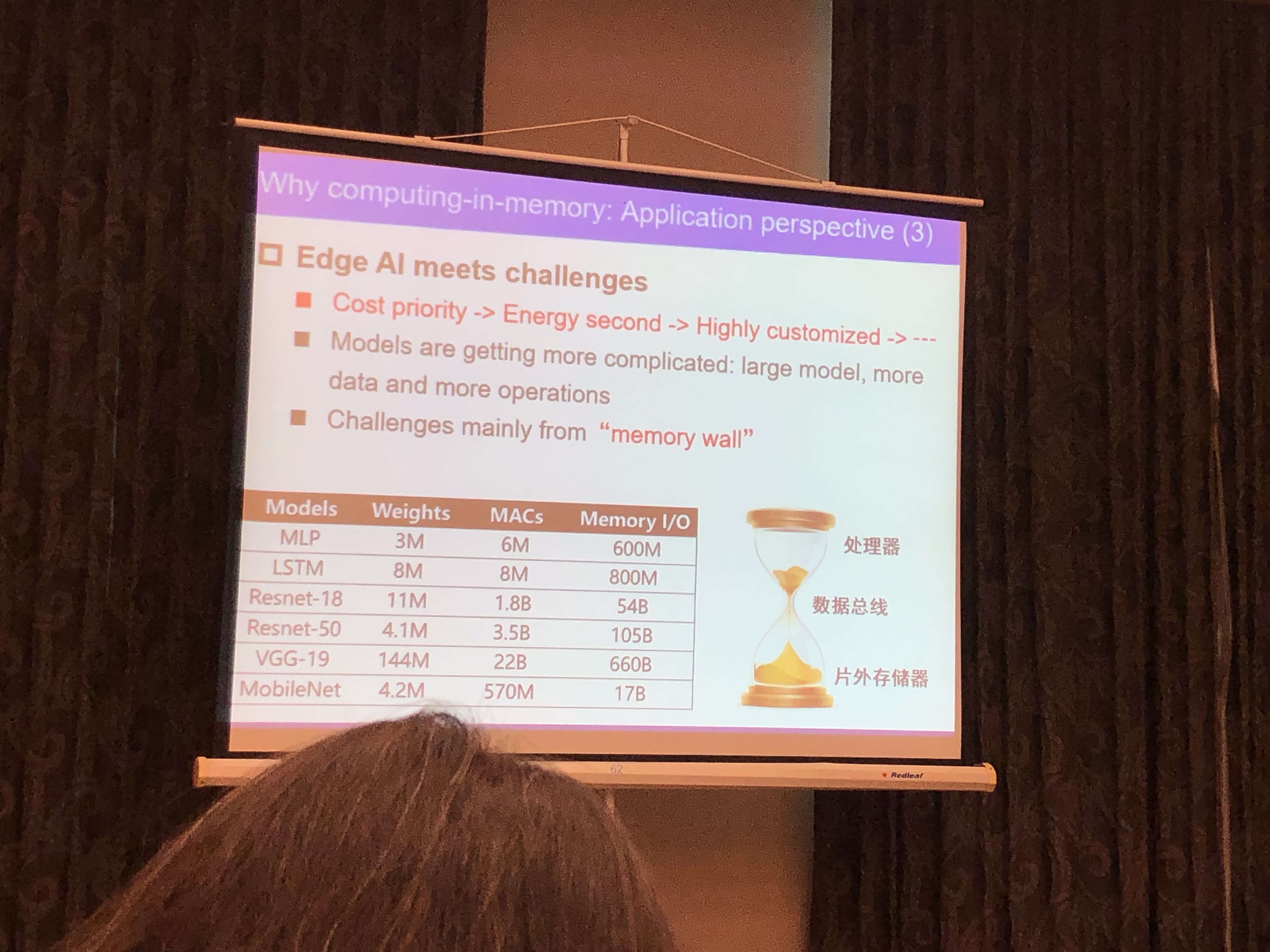
现有处理器系统问题
- 访存墙
近数据计算动机
- 非结构化数据占据数据中心80%的数据量
- 非结构化数据引起的访存开销巨大
- AI应用广泛
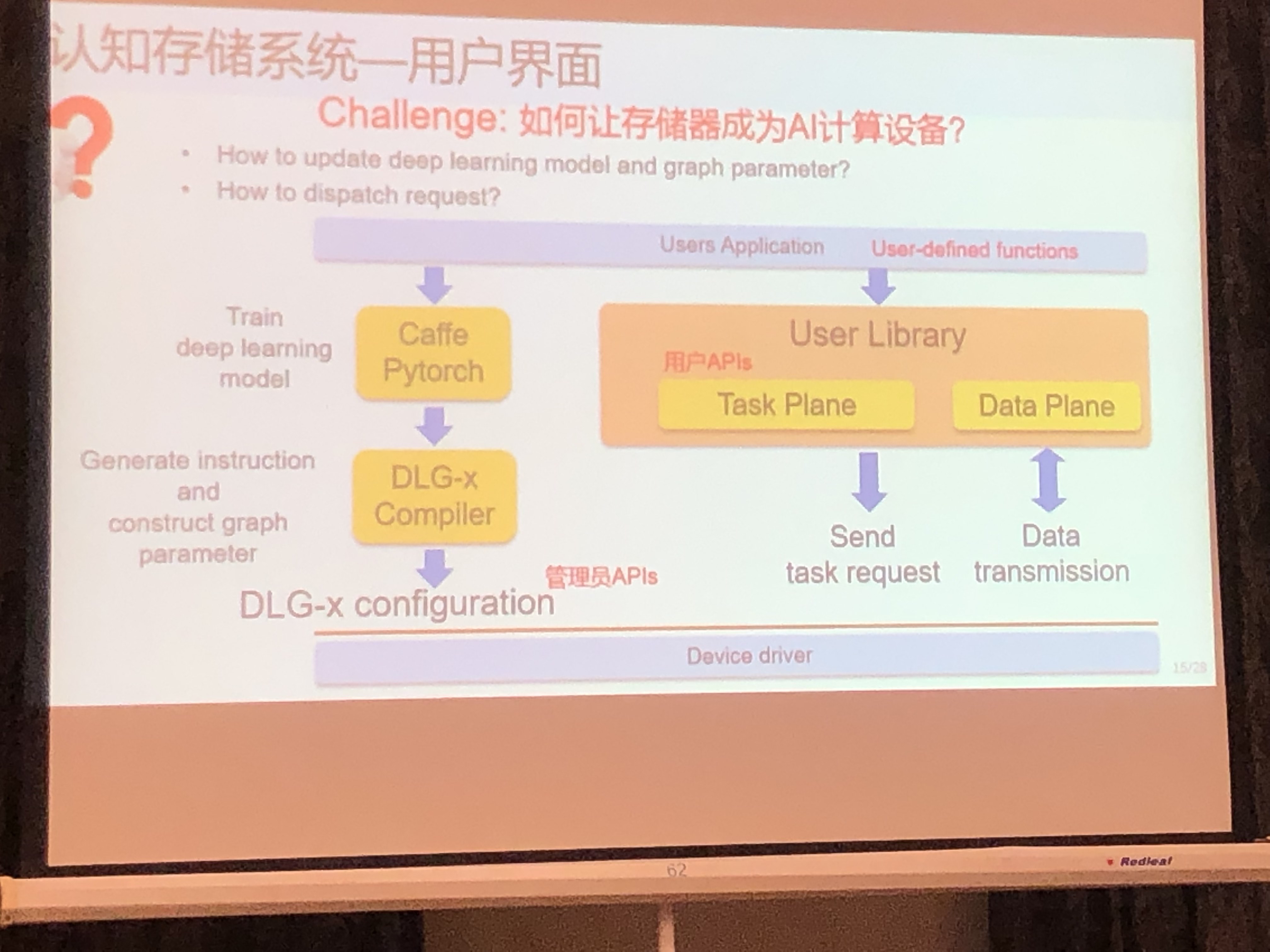
认知存储器挑战
- 简化系统与应用软件Stack:降低访存的软件瓶颈
- 近数据AI加速器:高带宽低延迟
- 软件API灵活
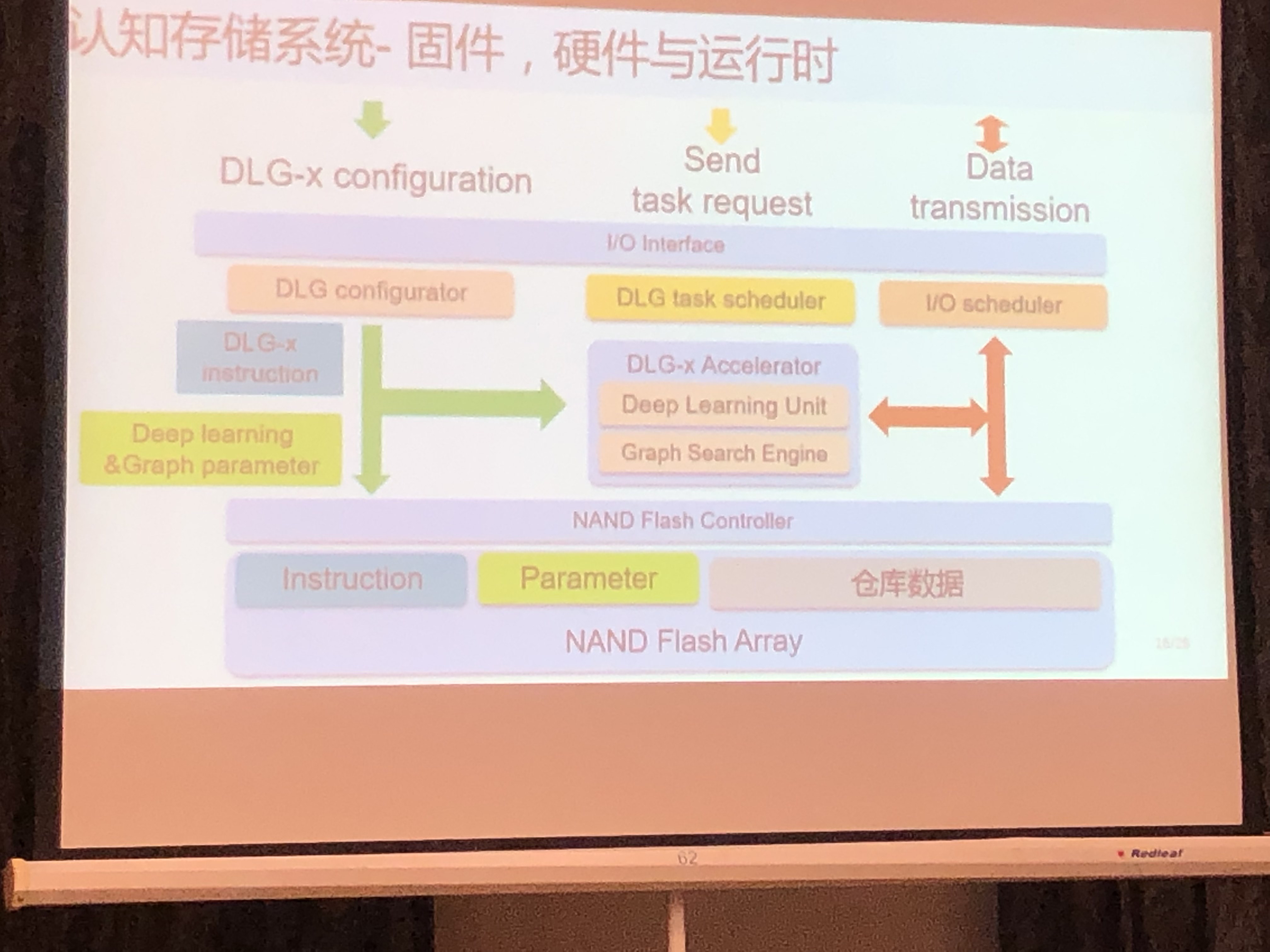
认知存储器系统设计
- User Library: DLG accelerator Library
- DLG Complier:DeepBurning2
- FrontEnd:Caffe/PyTorch
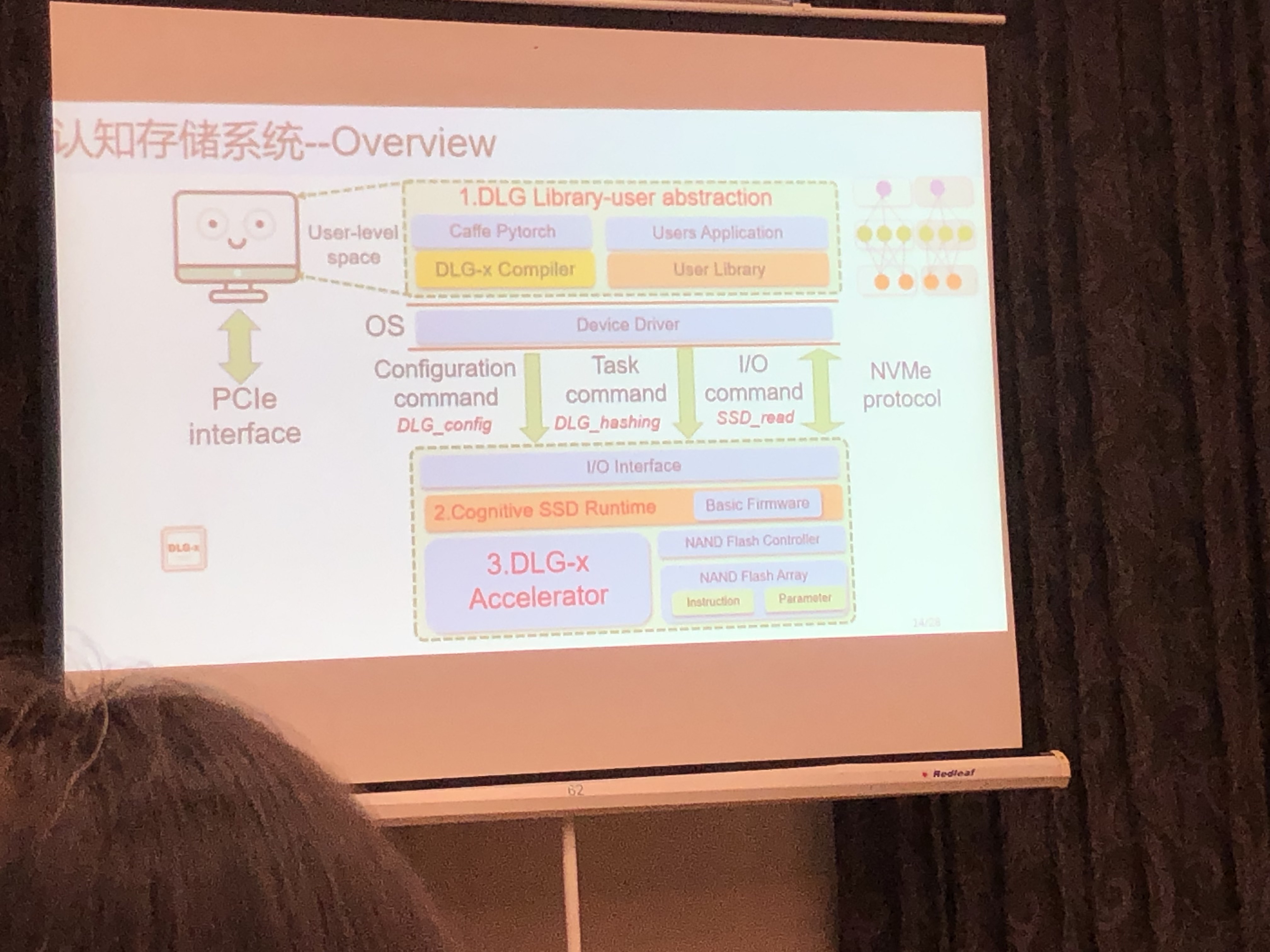
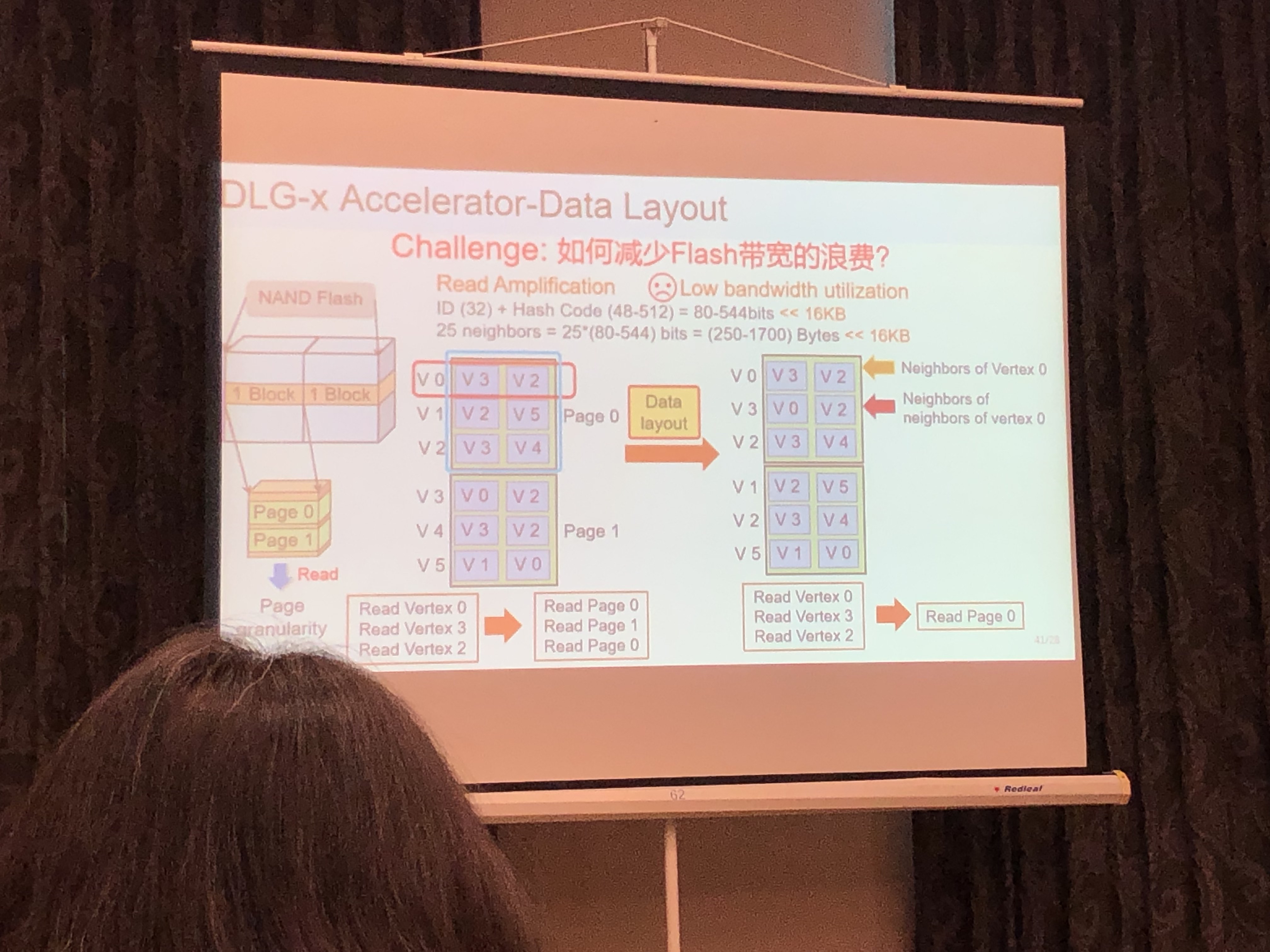
Deep Learning 加速器设计:DLG-x
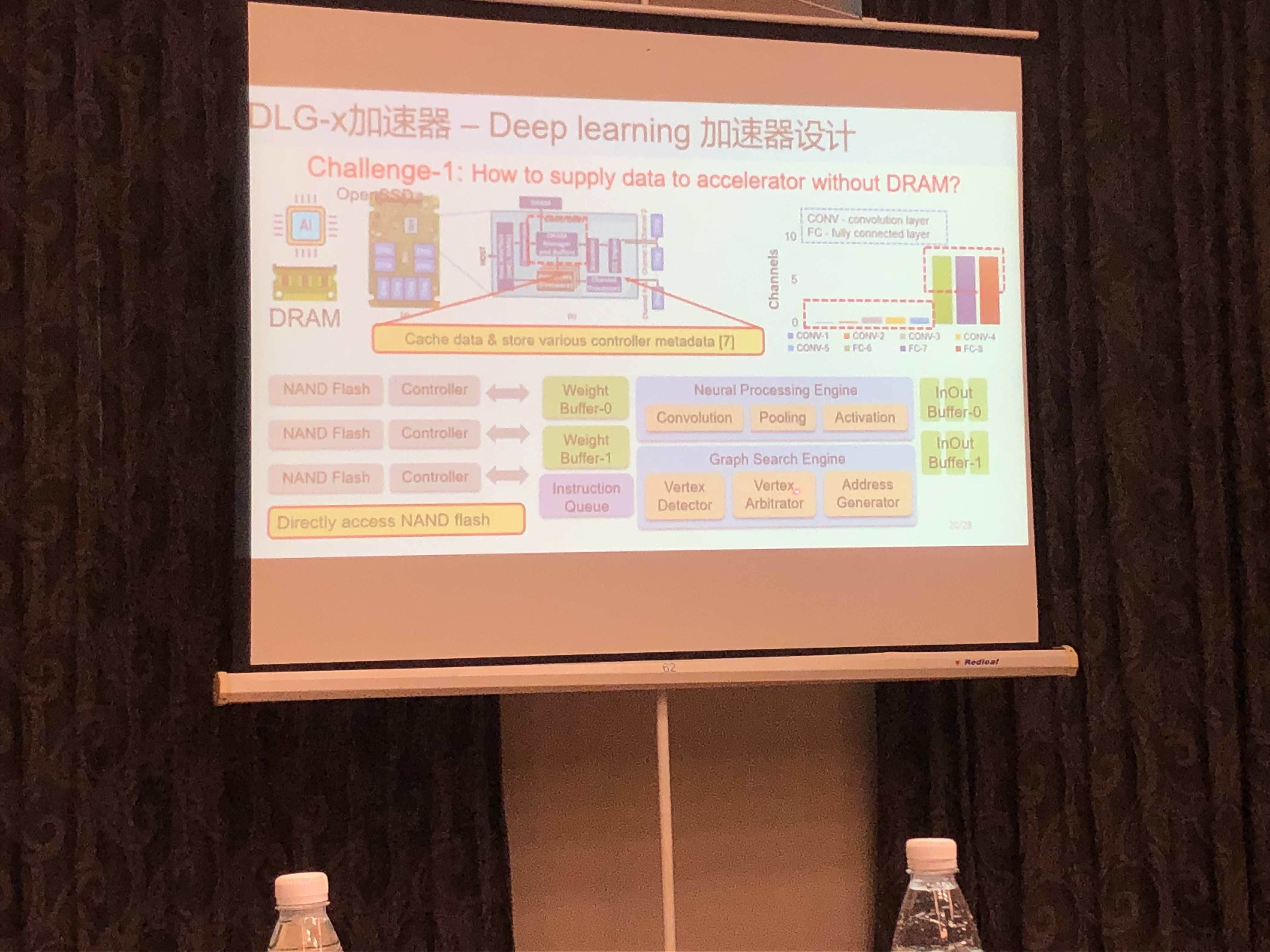
- 没有SRAM与DRAM:直接访问FLash
- 脉动阵列
- DeepBurning2:基于模版的AI硬件编译
- Data Layout优化:数据重排
- 性能优化:保留数据高位,抛弃低位(CNN容错特性)
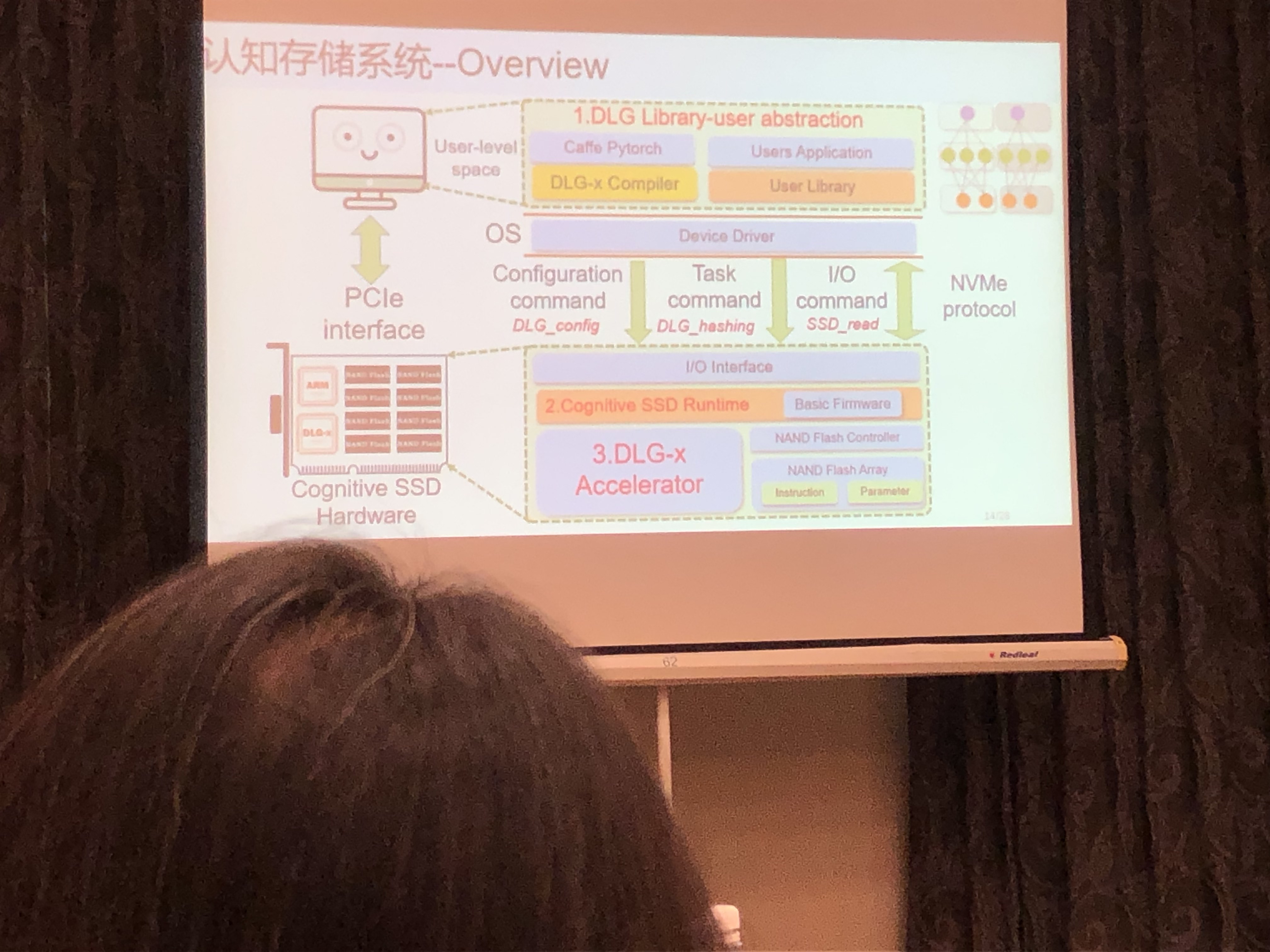
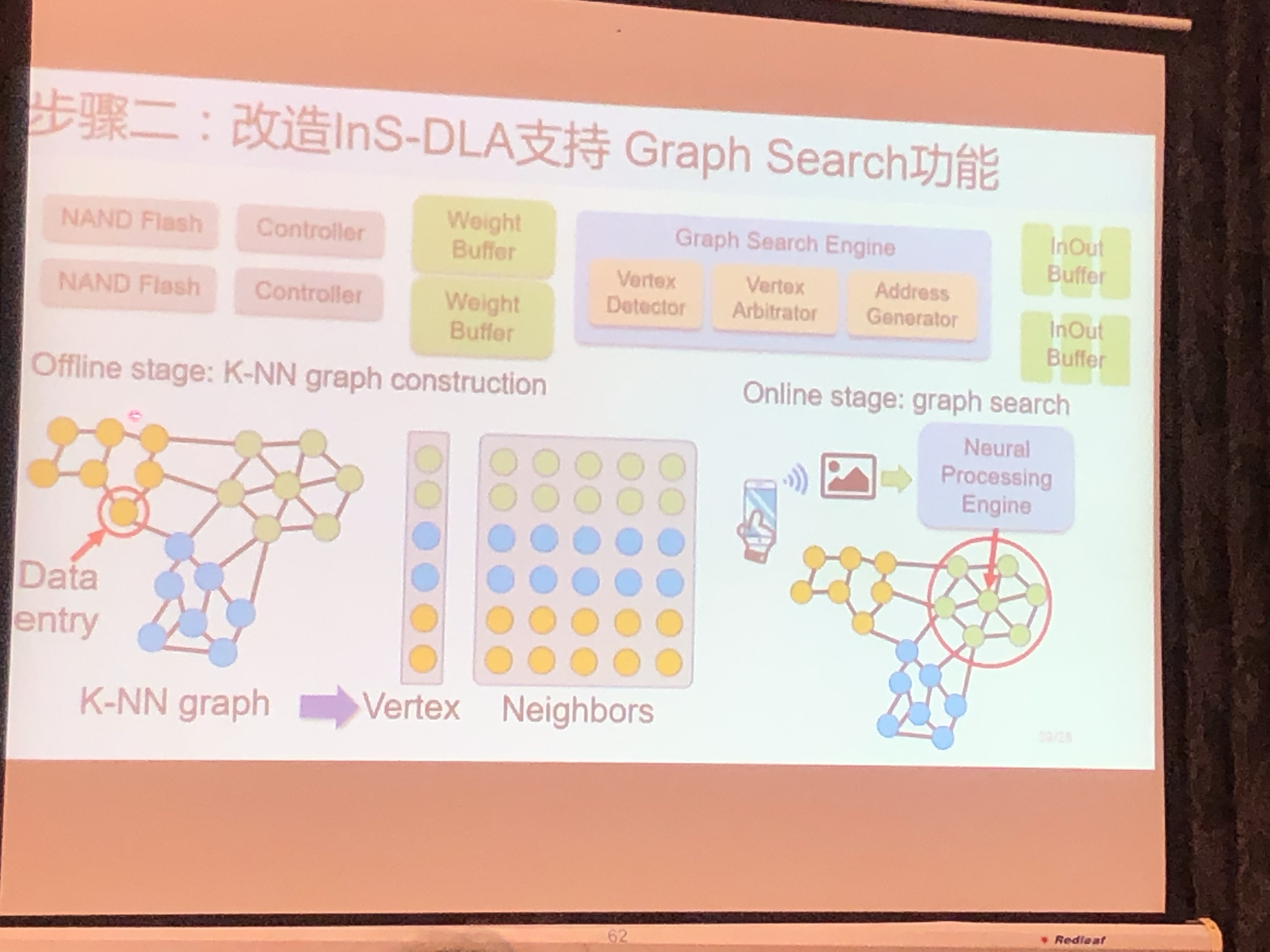
将Data Retrieval移植到认知存储器
- 用AI+图计算改变传统retrieval软件流程:本地实时认知;消除访存开销
- 改造InS-DLA支持Graph Search功能:KNN+Hash编码
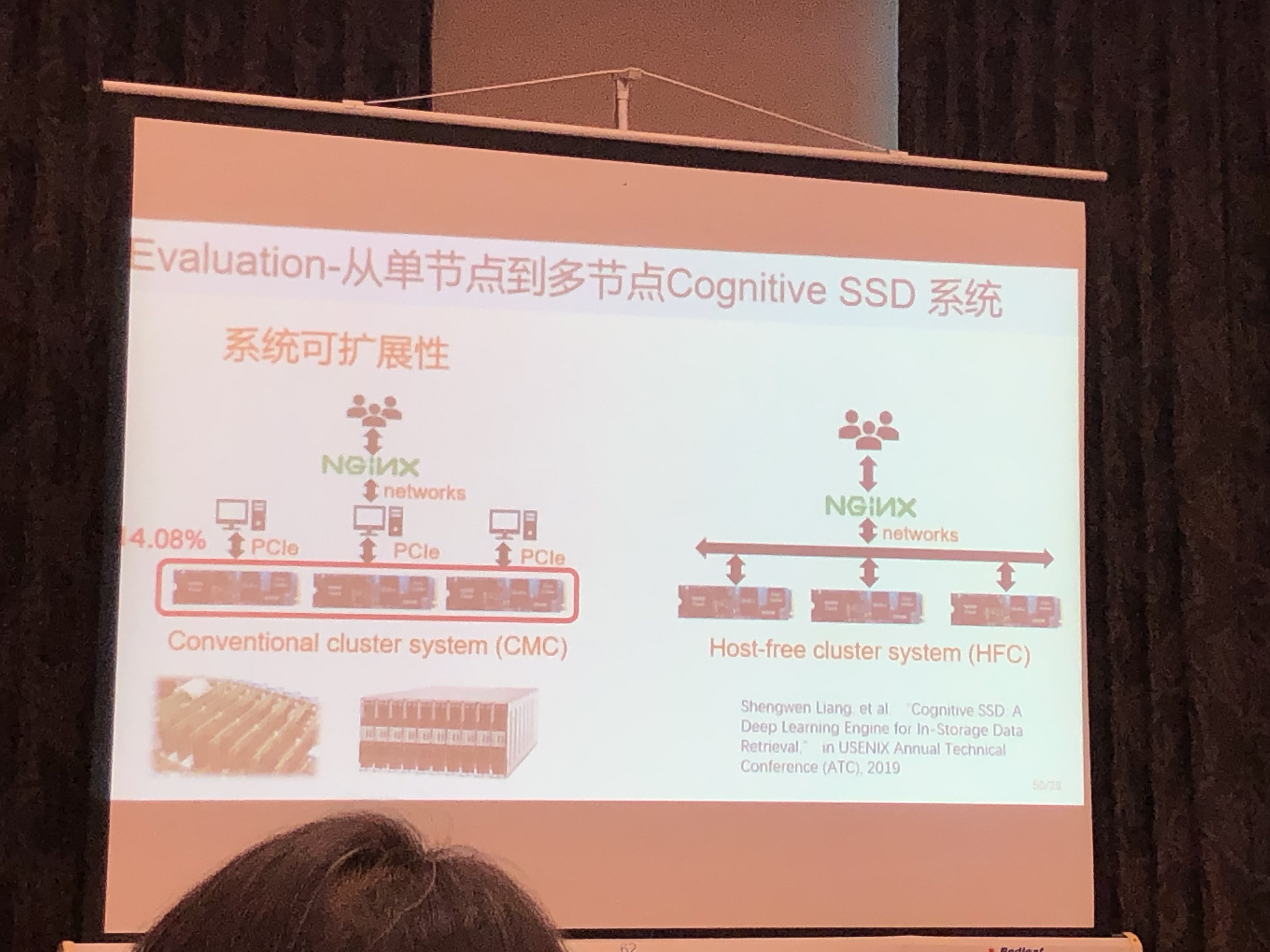
基于认知存储器的数据检索系统
- OPEN SSD开发板
- 37X-12.5X speedup over CPU




















自旋电子技术:从存储到存算一体
康旺 北航
由于本人对新型存储器件了解不多,这里不多总结,放上Keynote参考。





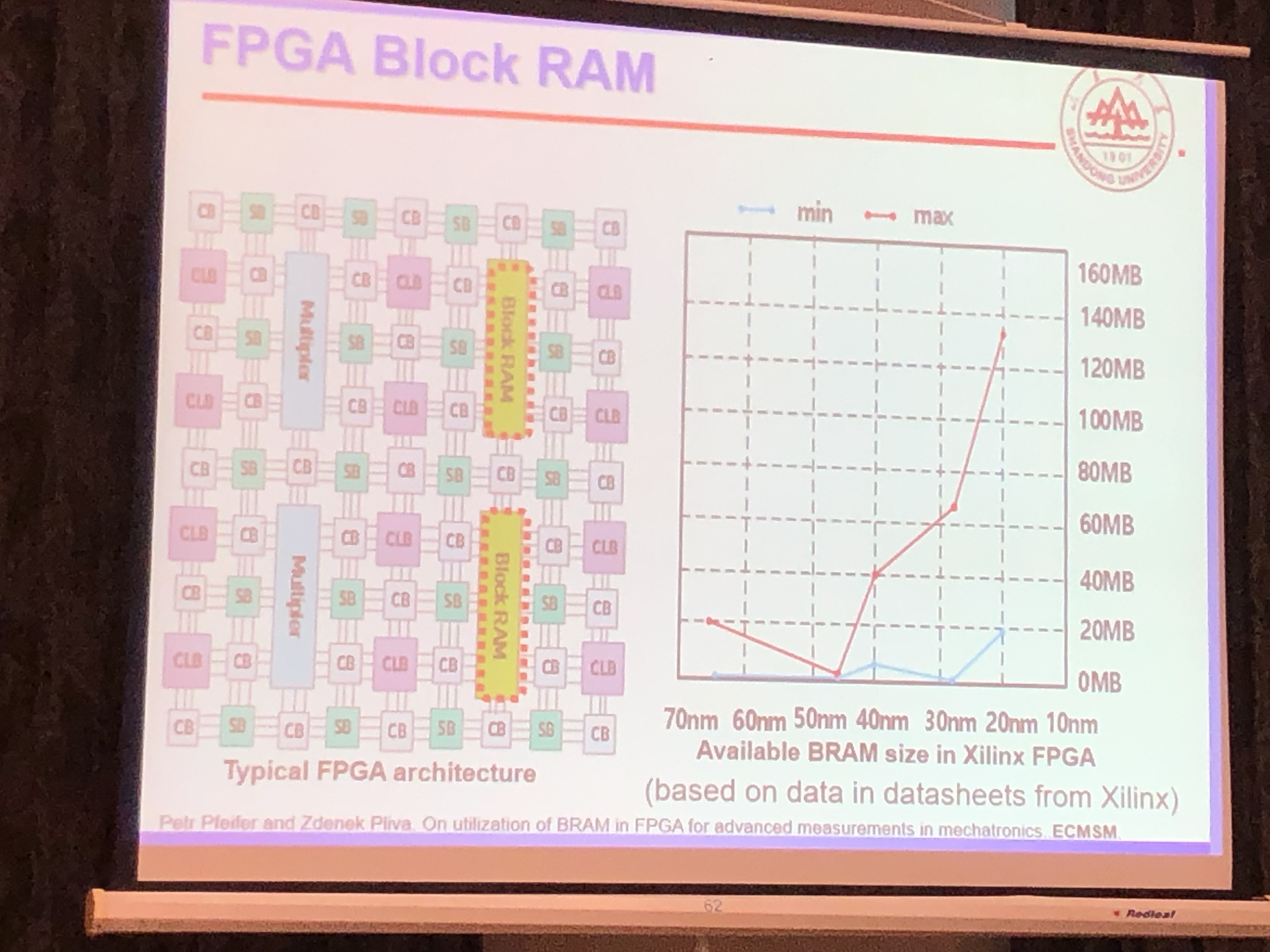
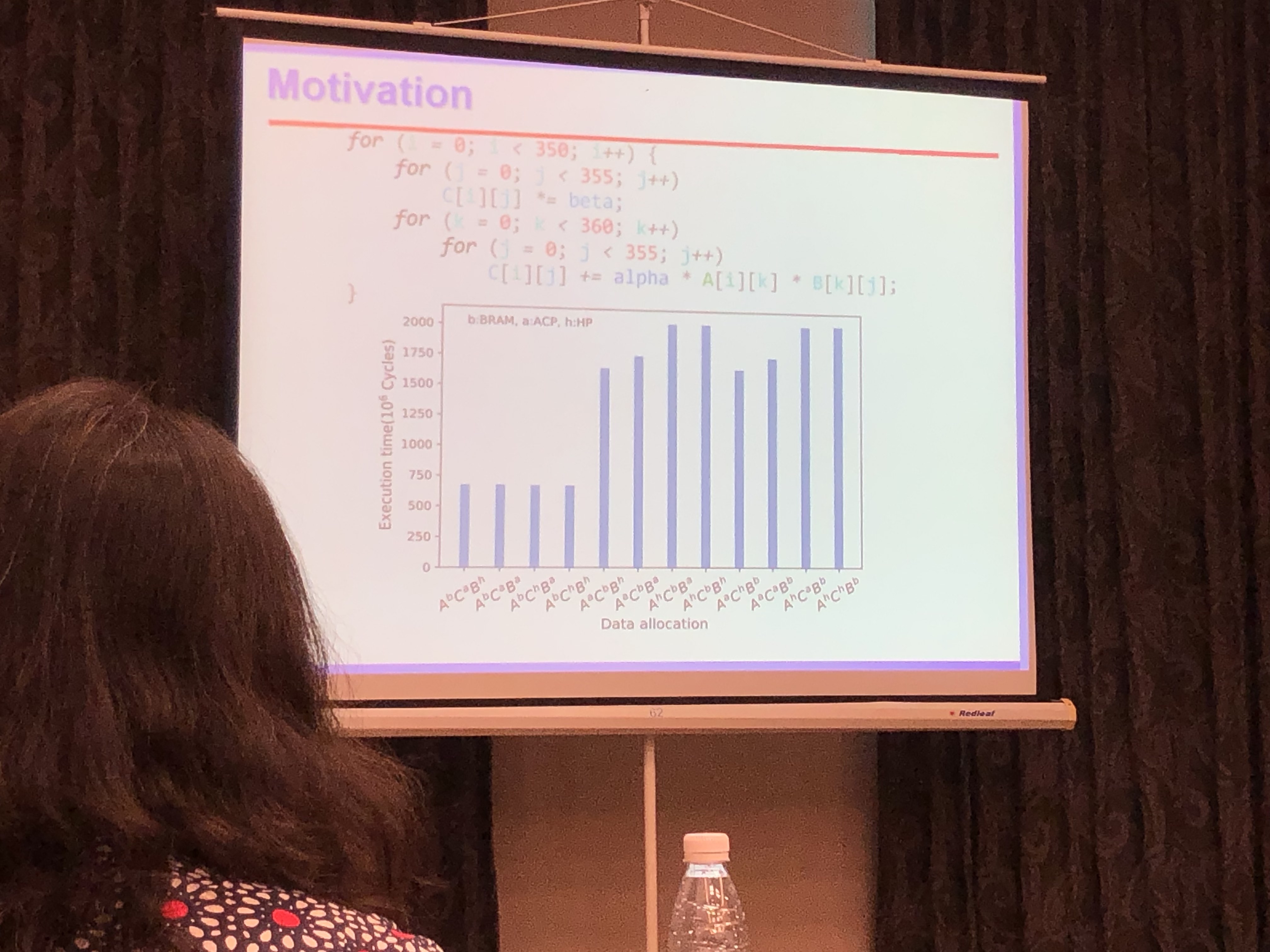
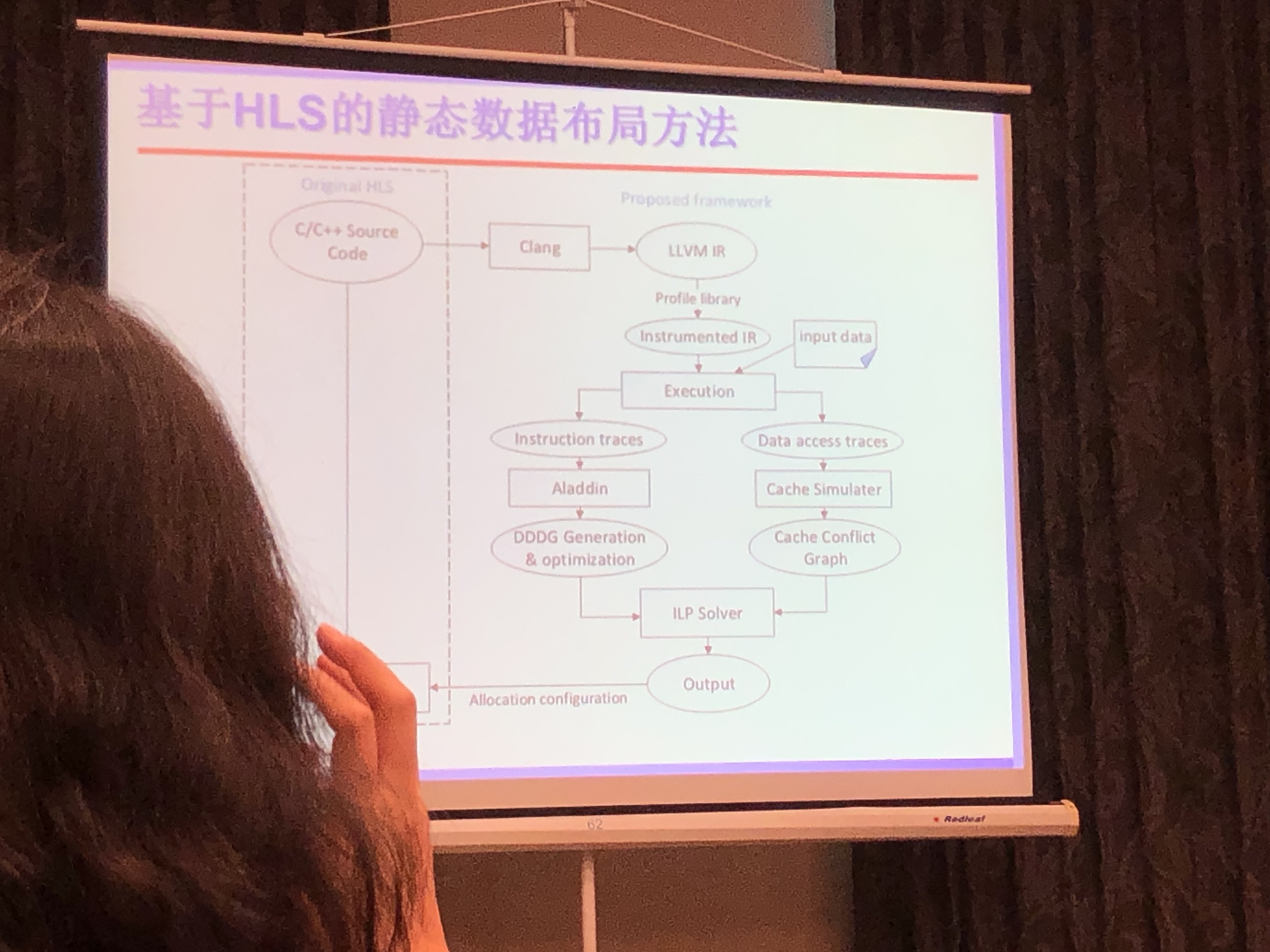
高能效FPGA片上存储结构设计及资源管理方法研究
鞠雷 山东大学
设计SLC-MLC混合的BRAM结构;通过编译器优化存储分配,提高访存性能。
- EDA优化存储分配;比如循环计算,不同的变量放在Cache,HP,BRAM,性能如何最优
- SLC-MLC Hybrid BRAM Architecture Design


可定制计算生态与全栈人才培养
陆佳华 Xilinx
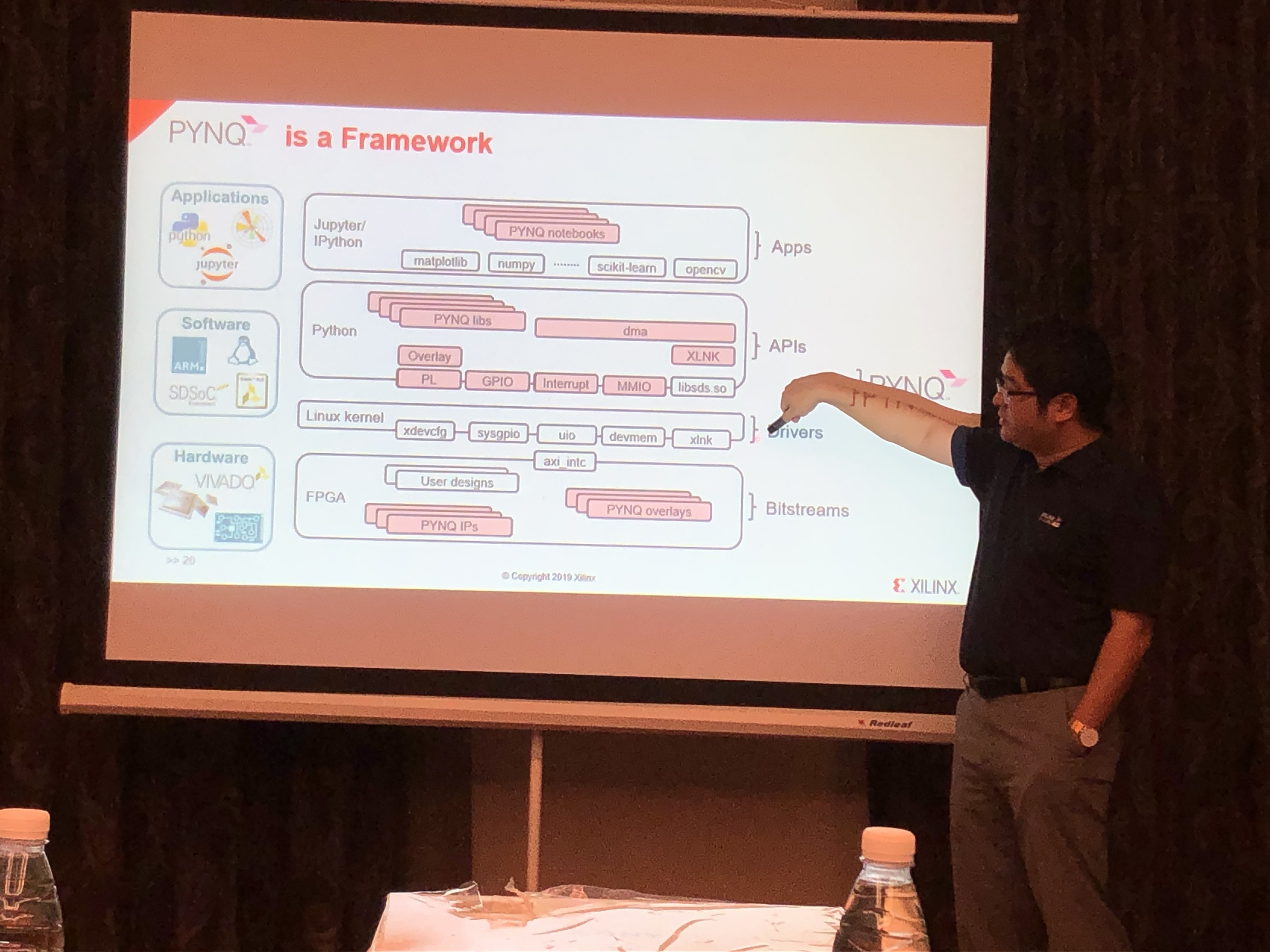
Pynq开发全栈介绍。
Pynq全栈框架
- Jupyter Ipython
- Python libs
- Linux Kernel
- FPGA
Pynq课程体系
- PYNQ-Z2
- 冬天有个课程针对PHD
- 公众号Xilnix学术合作回复pp4fpgas和mpsocbook获取相关电子资料


Reconfigurable Computing and AI Chips
尹首一 清华大学
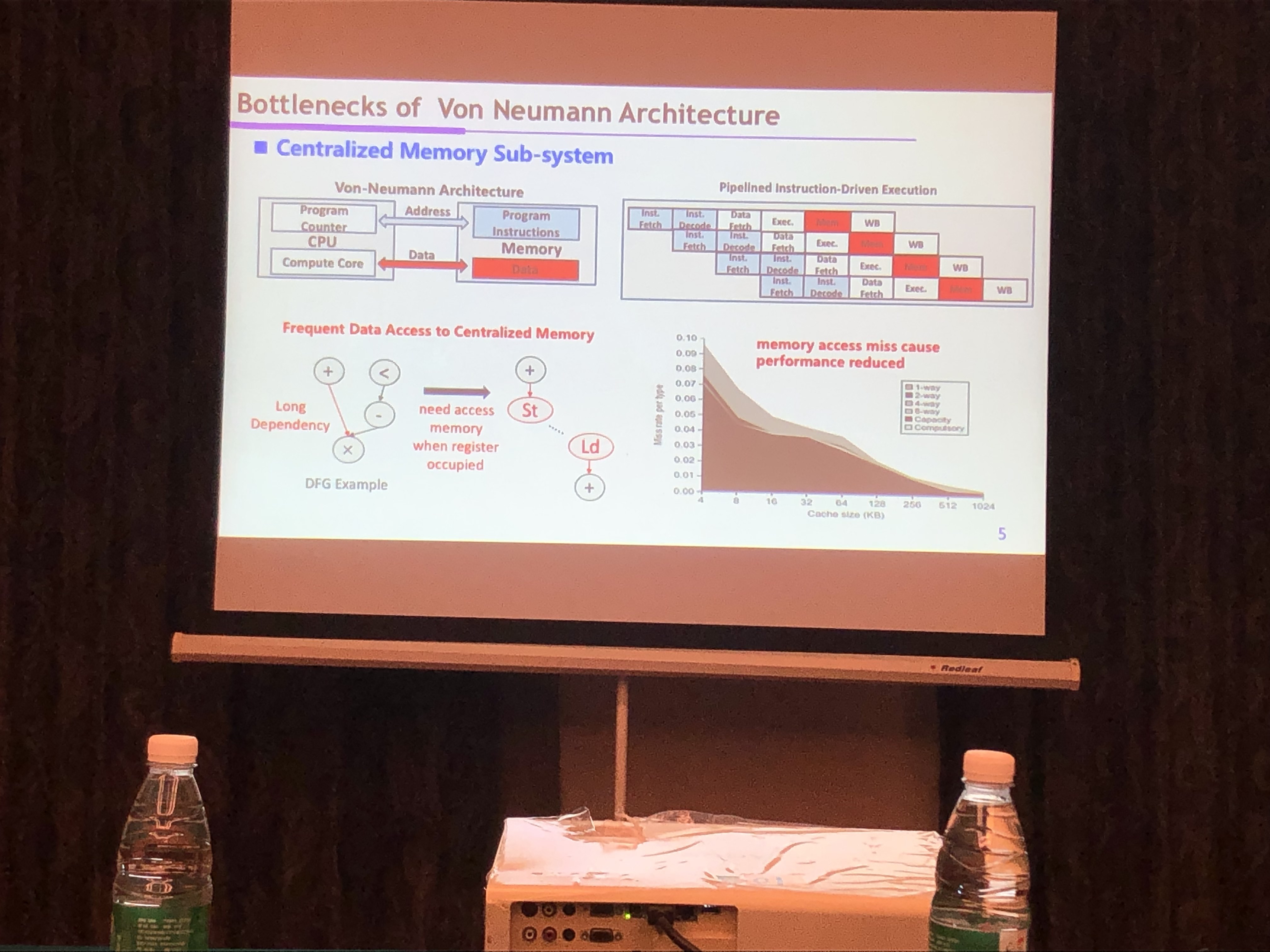
为了解决冯诺伊曼结构的瓶颈问题,可重构计算带来了一条新路子。
冯诺伊曼结构瓶颈
- 指令部分消耗大量时间:译码、发射
- 存储墙
- 固定位宽计算:浪费存储空间与计算能力
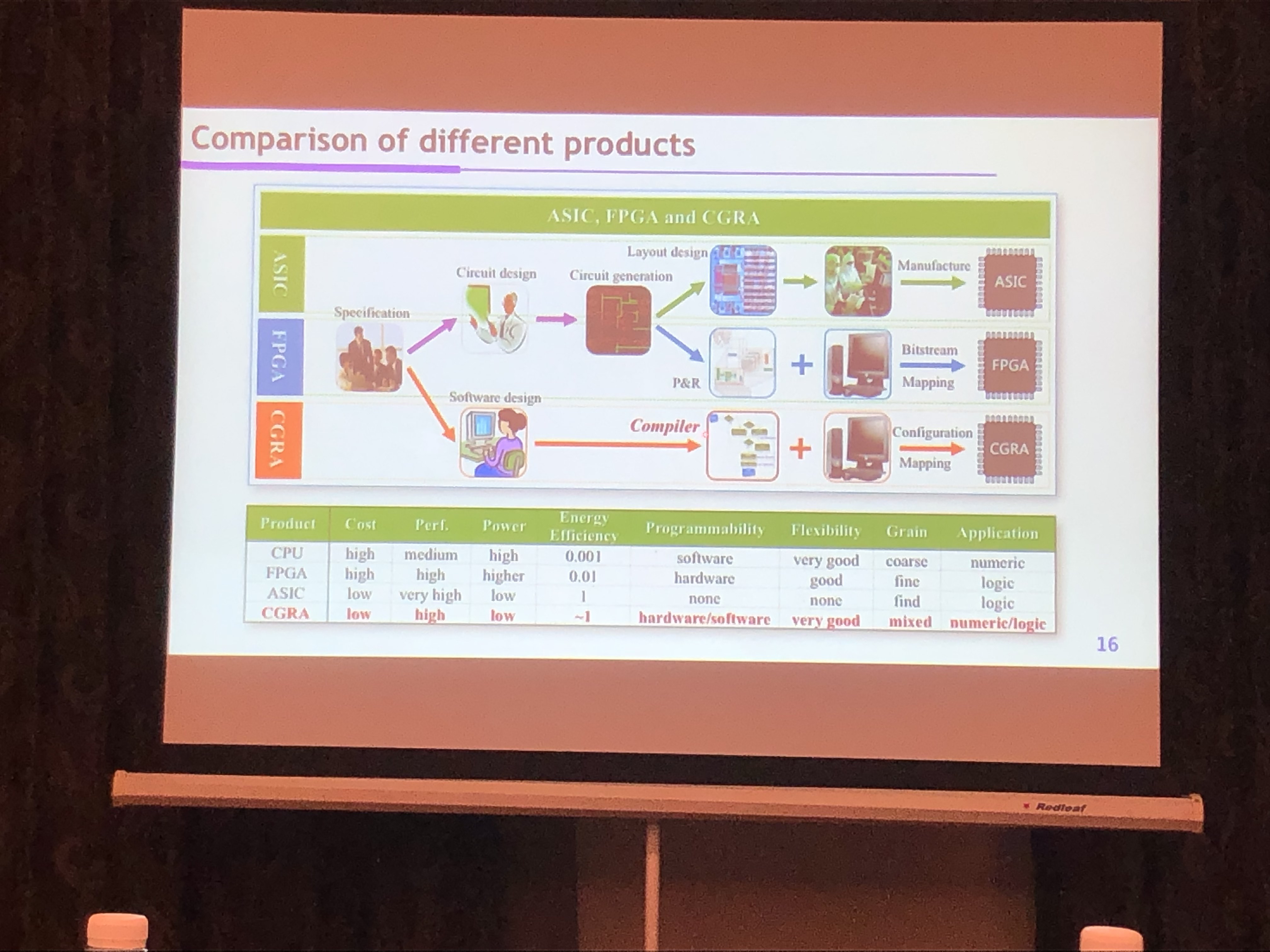
可重构计算
- 软件定义硬件:重构时延要求300-1000ns
- 粗粒度的可重构架构(不像FPGA的细腻度)
CGRA结构:分布式存储,无指令、灵活位宽
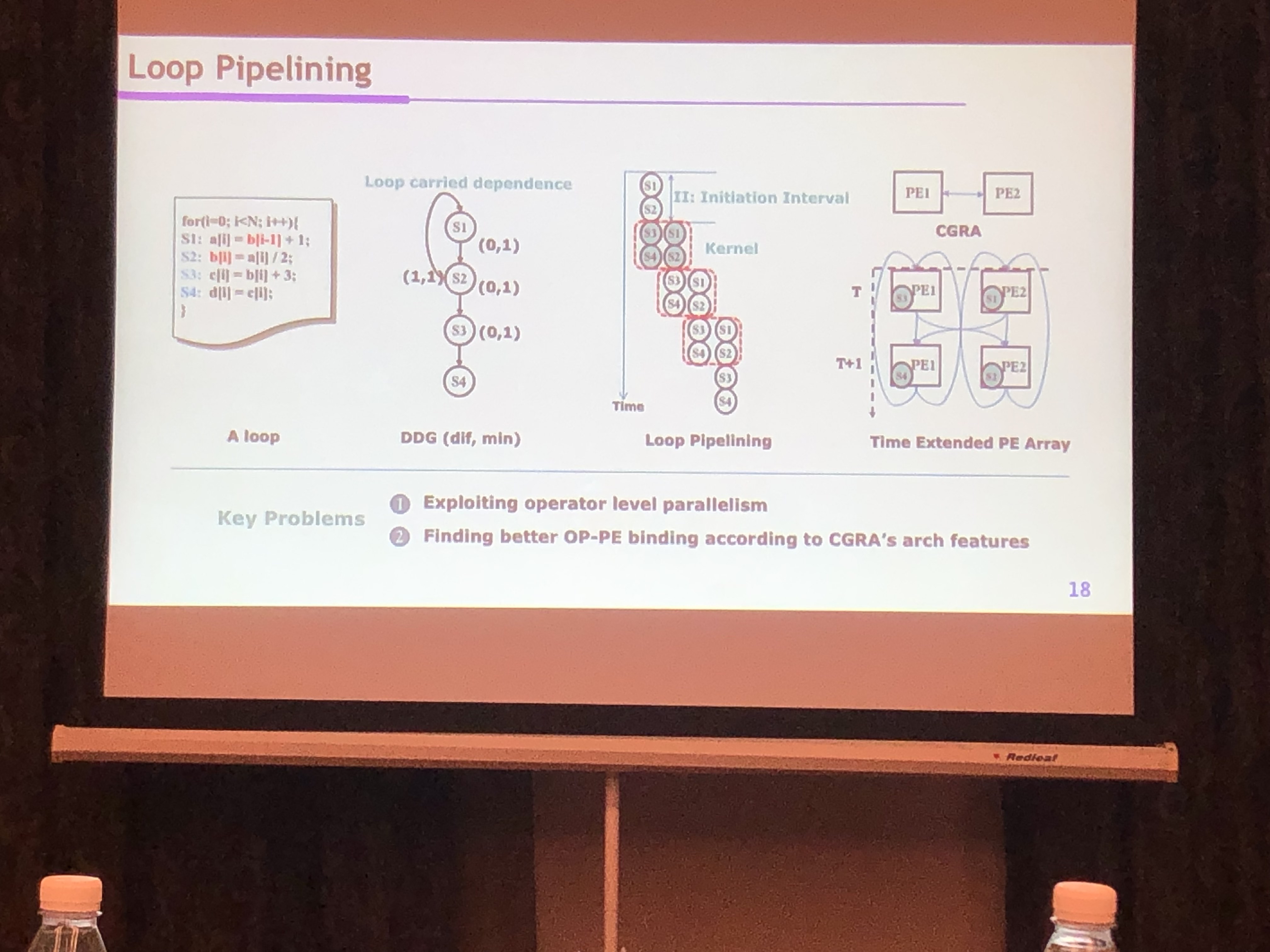
- 软件定义路径
- 循环流水
- 通用能力 13项workloads
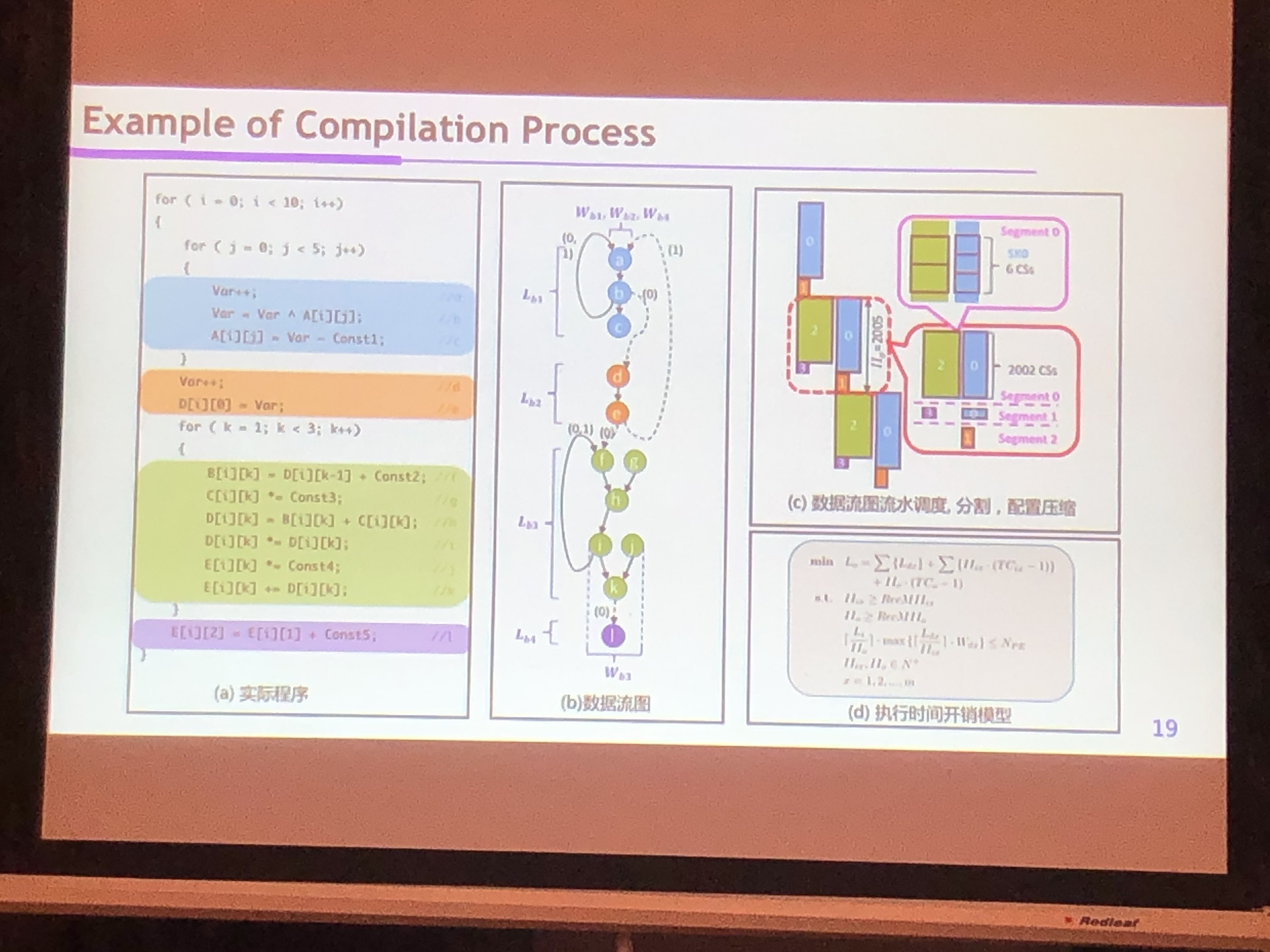
- 基于数据流的编译系统
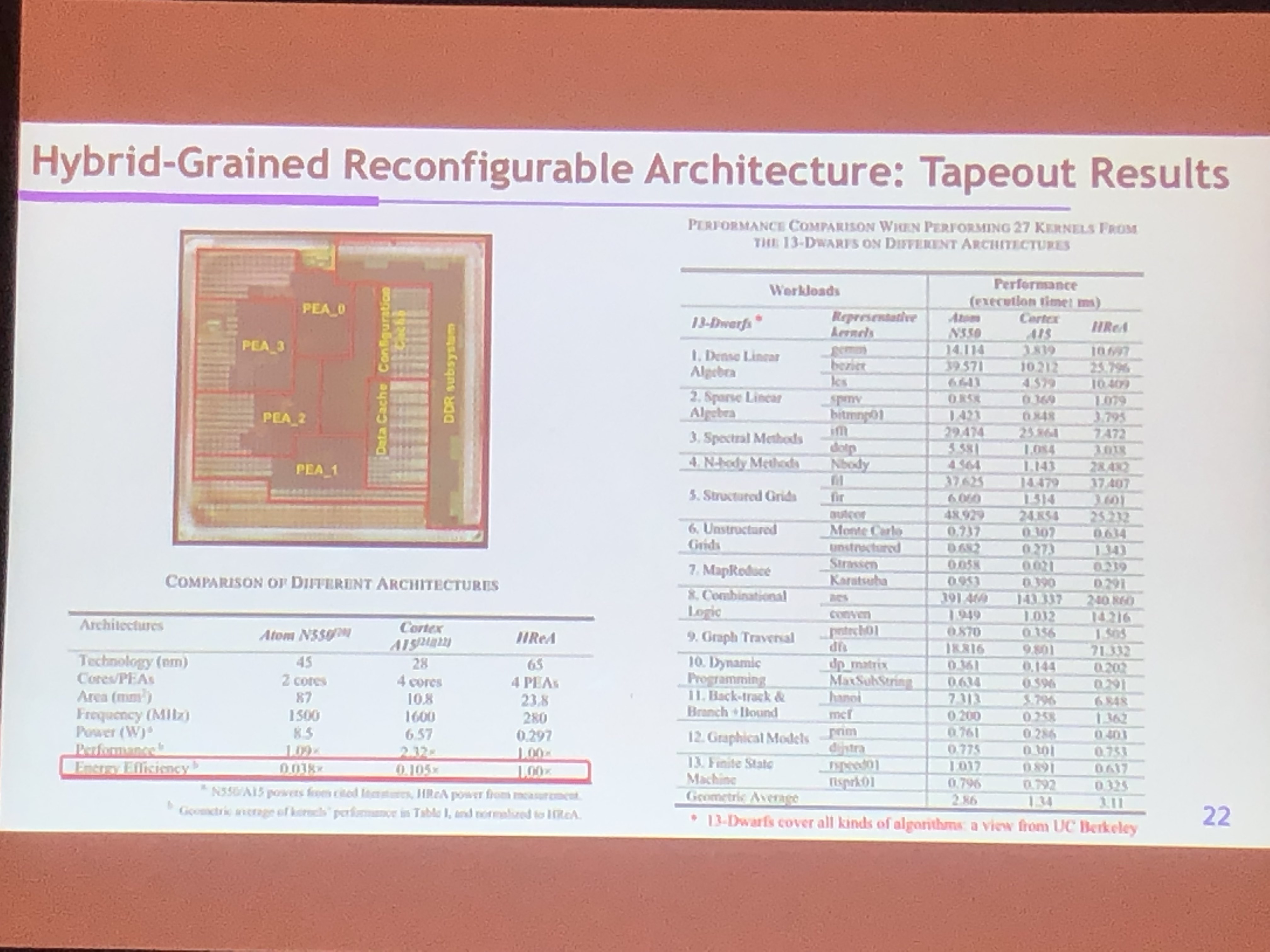
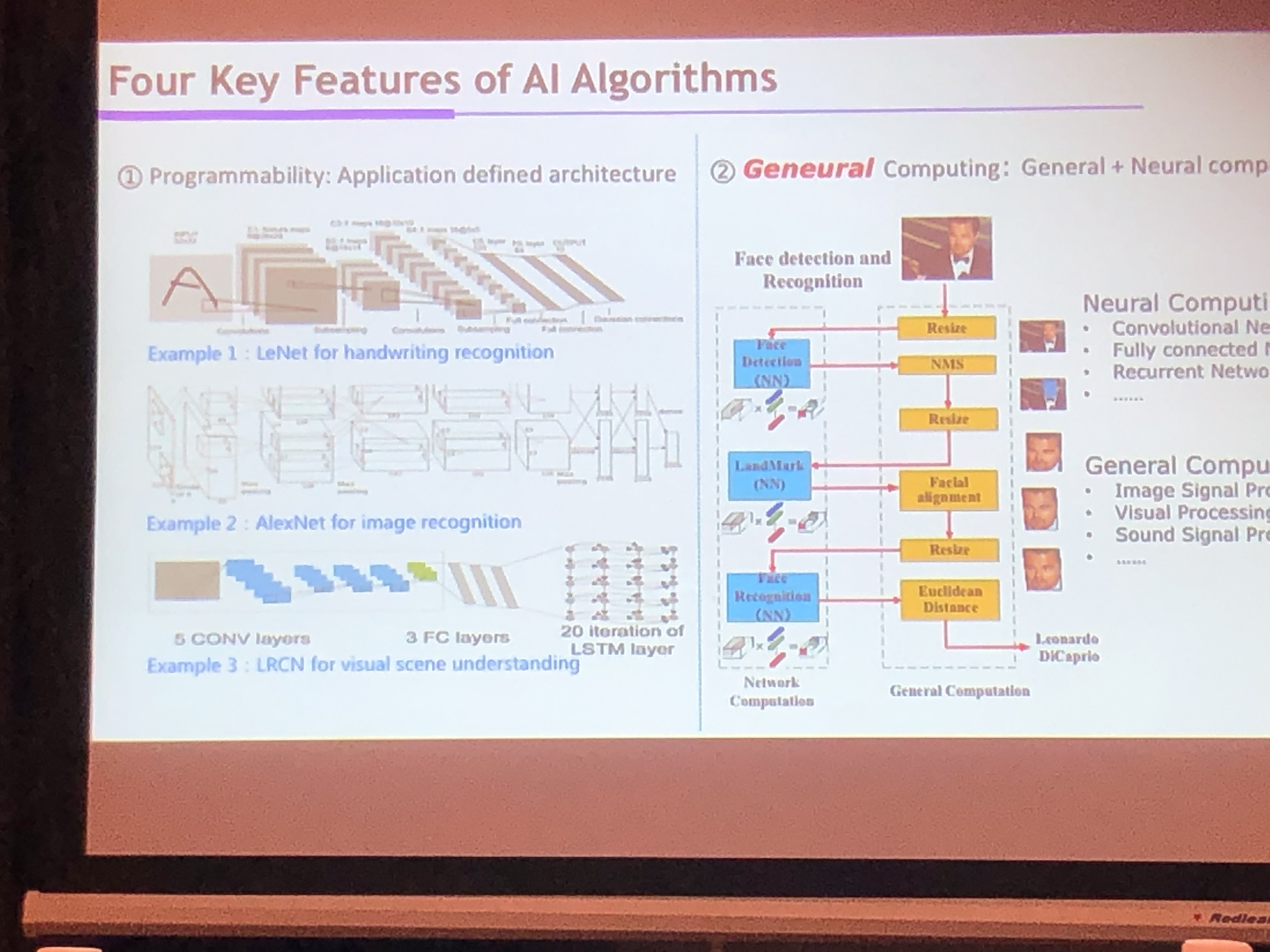
可重构AI芯片
- CONV:七层循环体
- 四个关键特性
- 可编程能力
- Geneural:General(NMS等) + Neural Computing
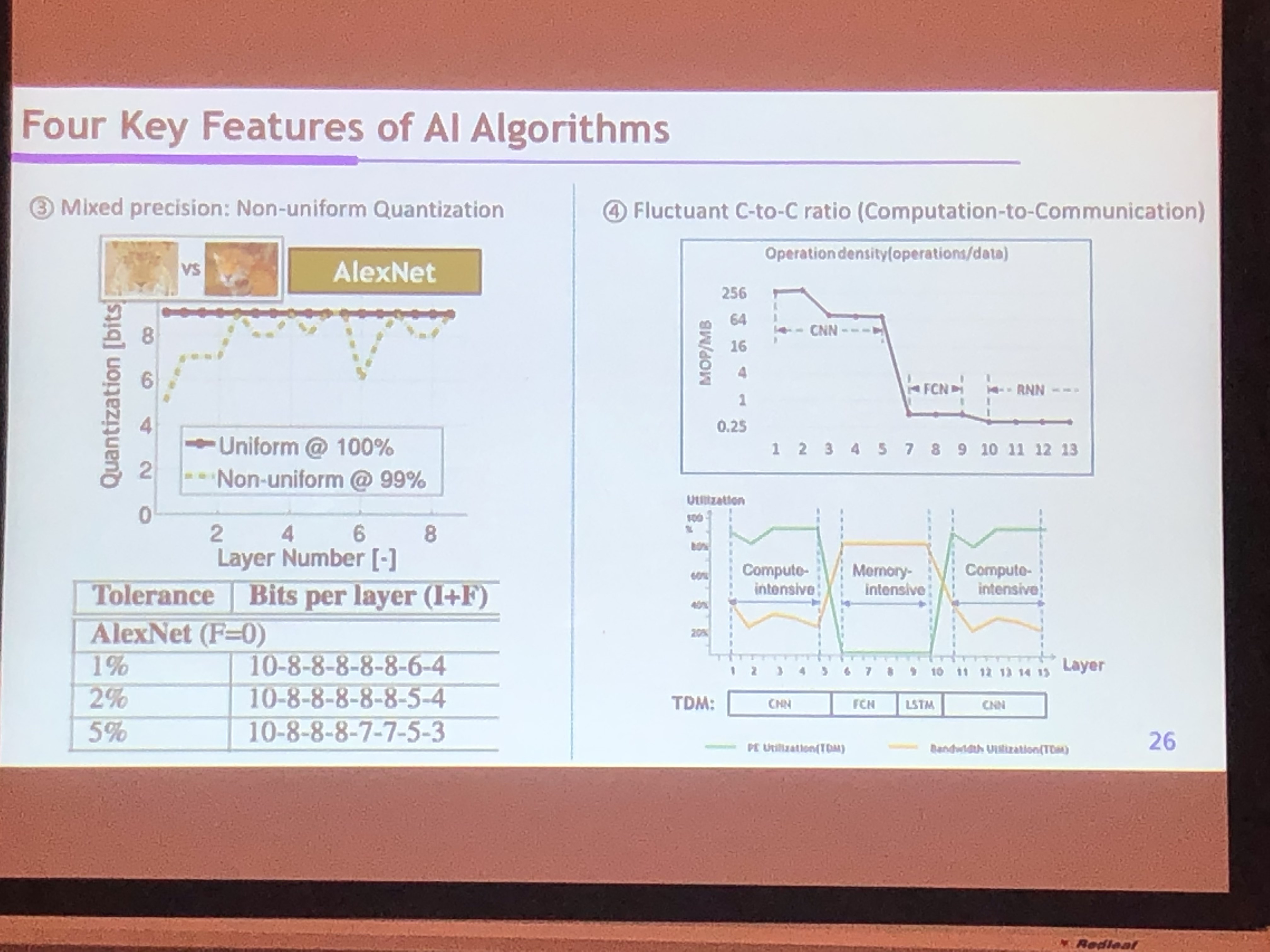
- 混和精度
- 计算访存比波动
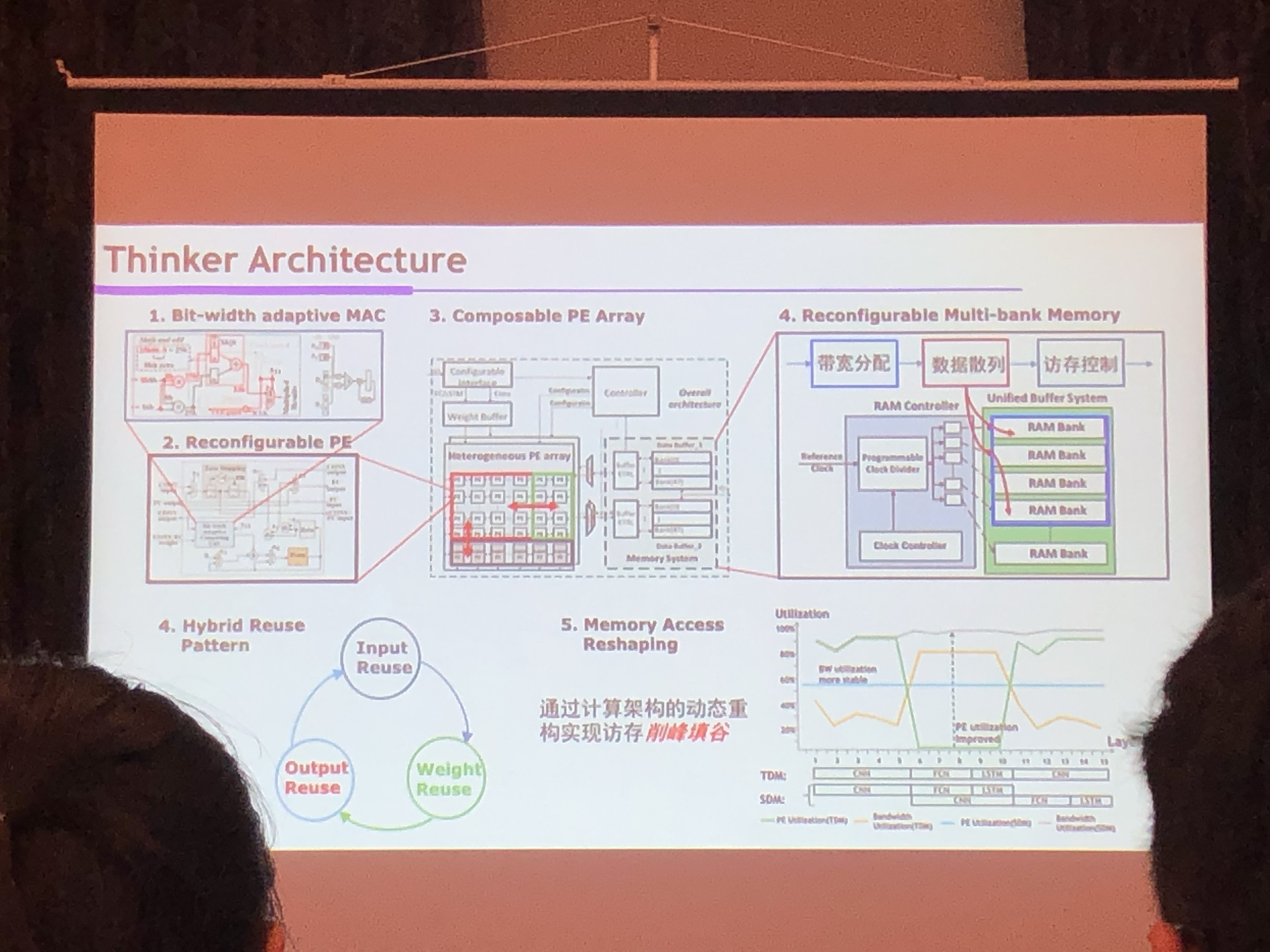
- AI结构优化
- Bit-width adaptive MAC
- Reconfigurable PE
- Composable PE Array
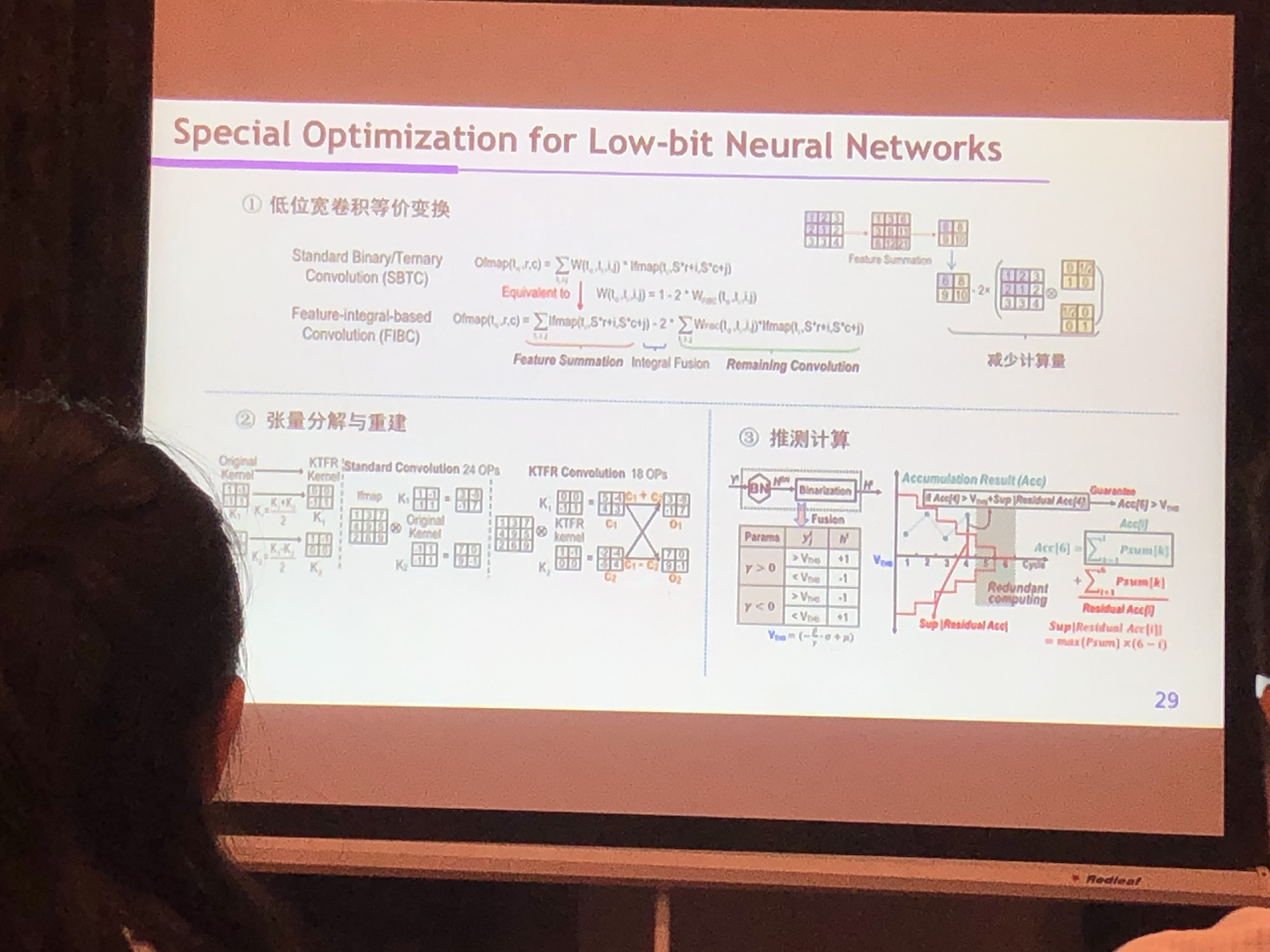
- 低bit NN的优化
- 低bit卷积等价变换
- 张量分解与重建
- 推测计算
- 阈值预测
- AI Compiler Stack
- TVM
- 四款Thinker AI 处理器








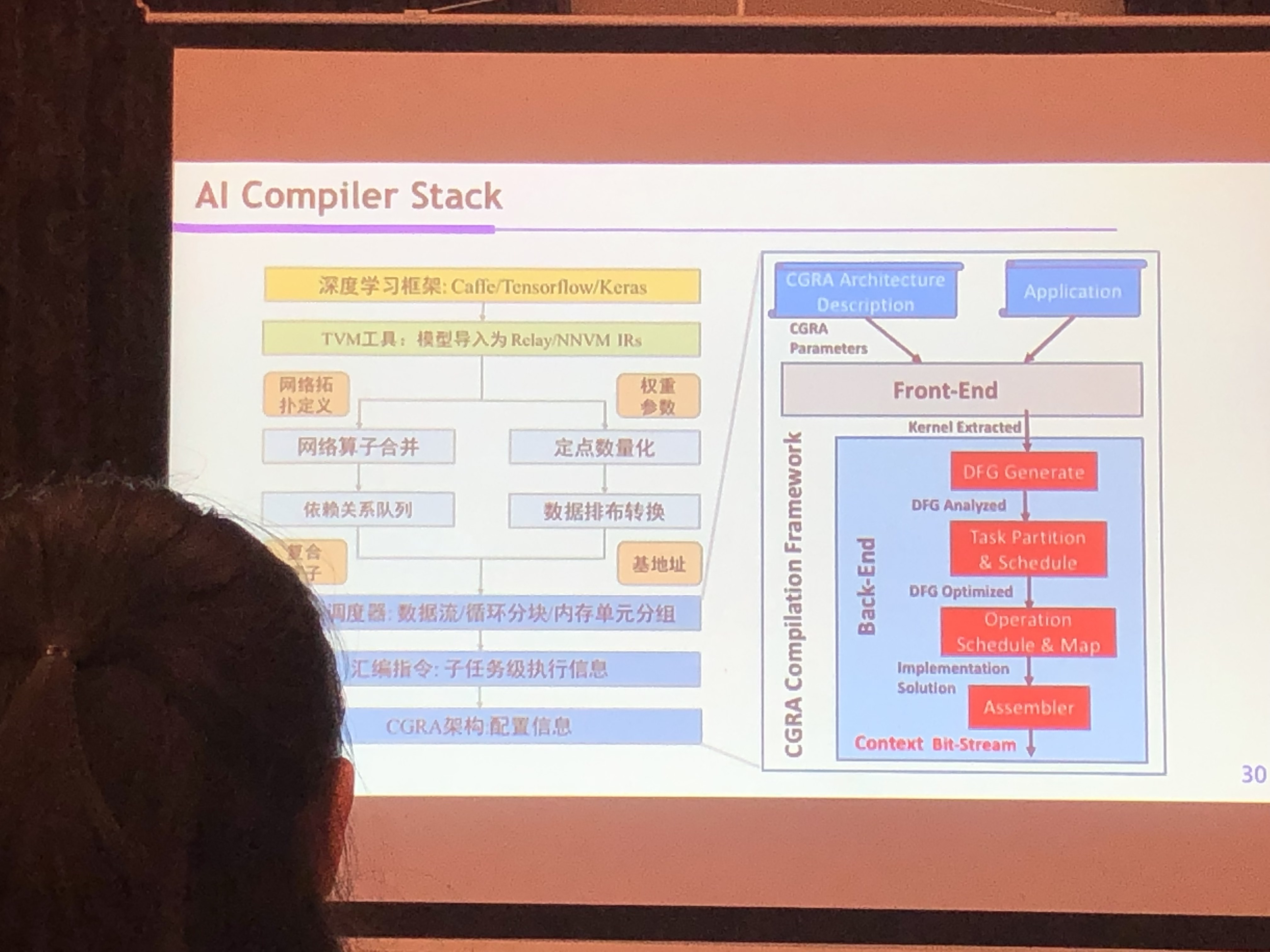

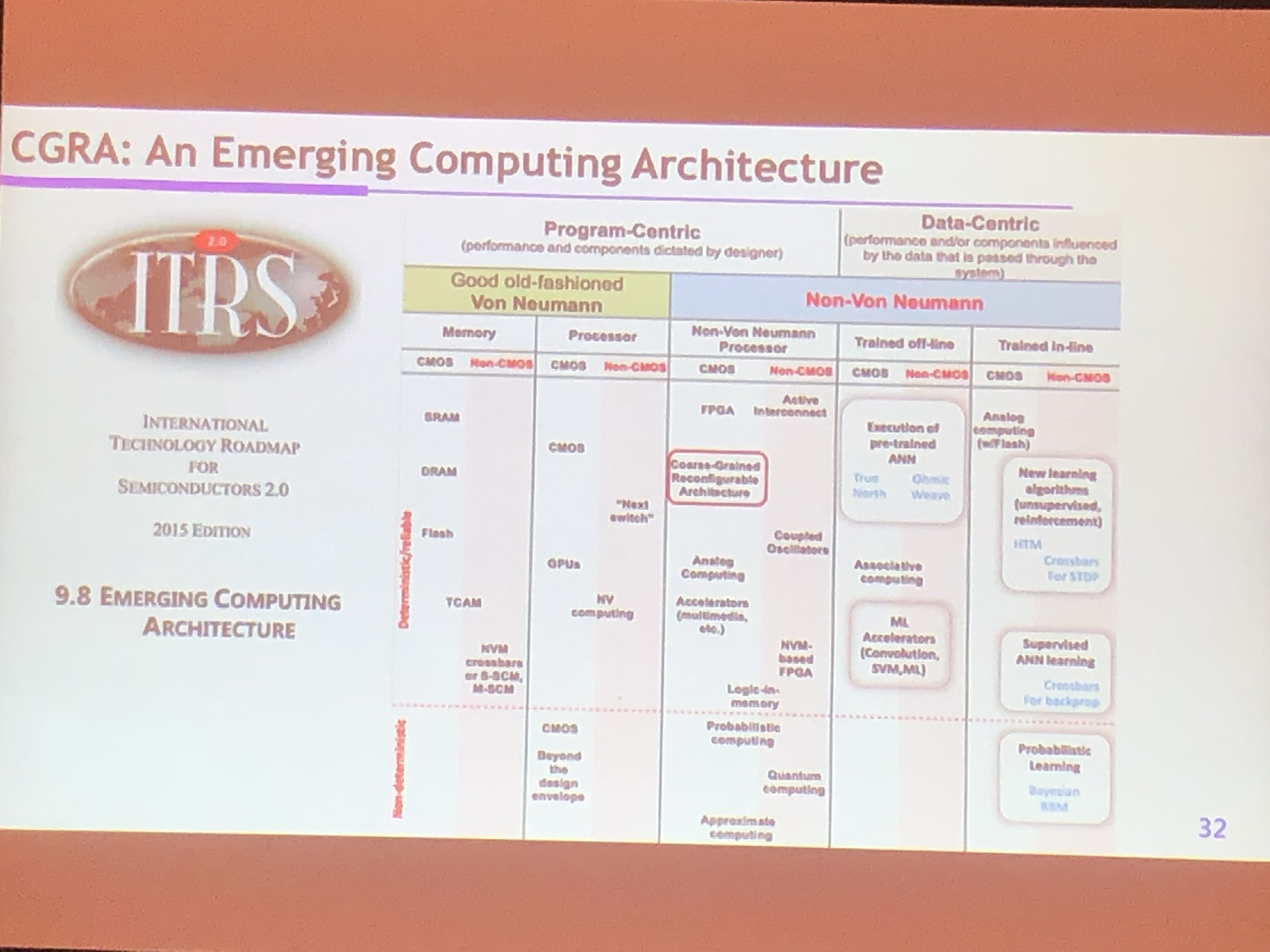
以开放工具链构建开源SoC设计方法学
马立伟 SiFIve
新的硬件设计语言Chisel带来更高的设计灵活性和效率;SiFIve推出新的开源EDA解决方案。
开源Rocket-Chip:RISC-V Core
Chisel
- 不是HLS
- function 编程
- Verilog/VHDL是描述电路行为用的;Chilsel是在描述电路的结构
- metaprogramming
开源EDA工具链
- Diplomacy TileLinke
- 三个开源工具 Wit、DuH、Wake

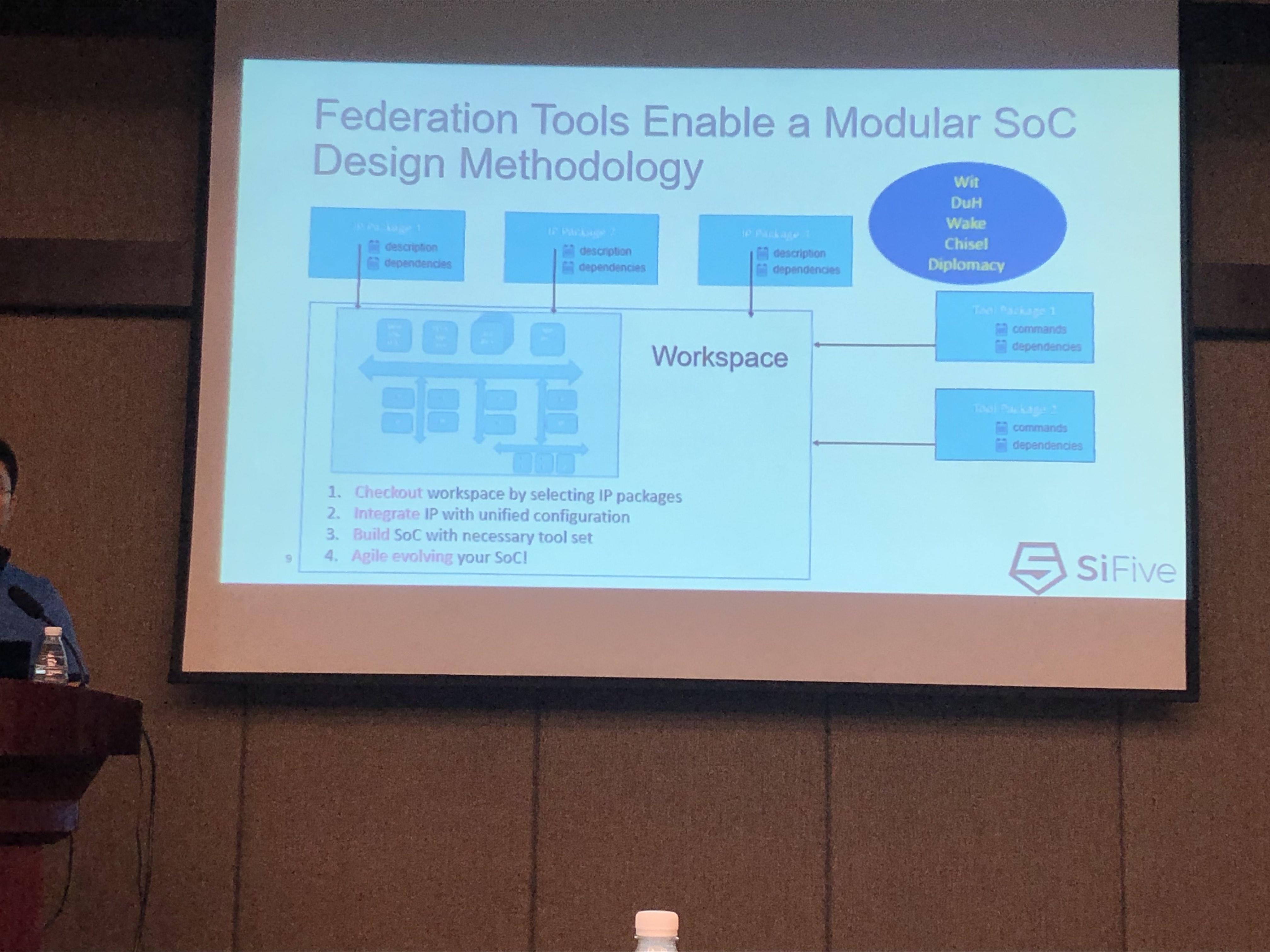


敏捷开发实践与开源EDA工具链
解壁伟 中科院计算所包云冈团队
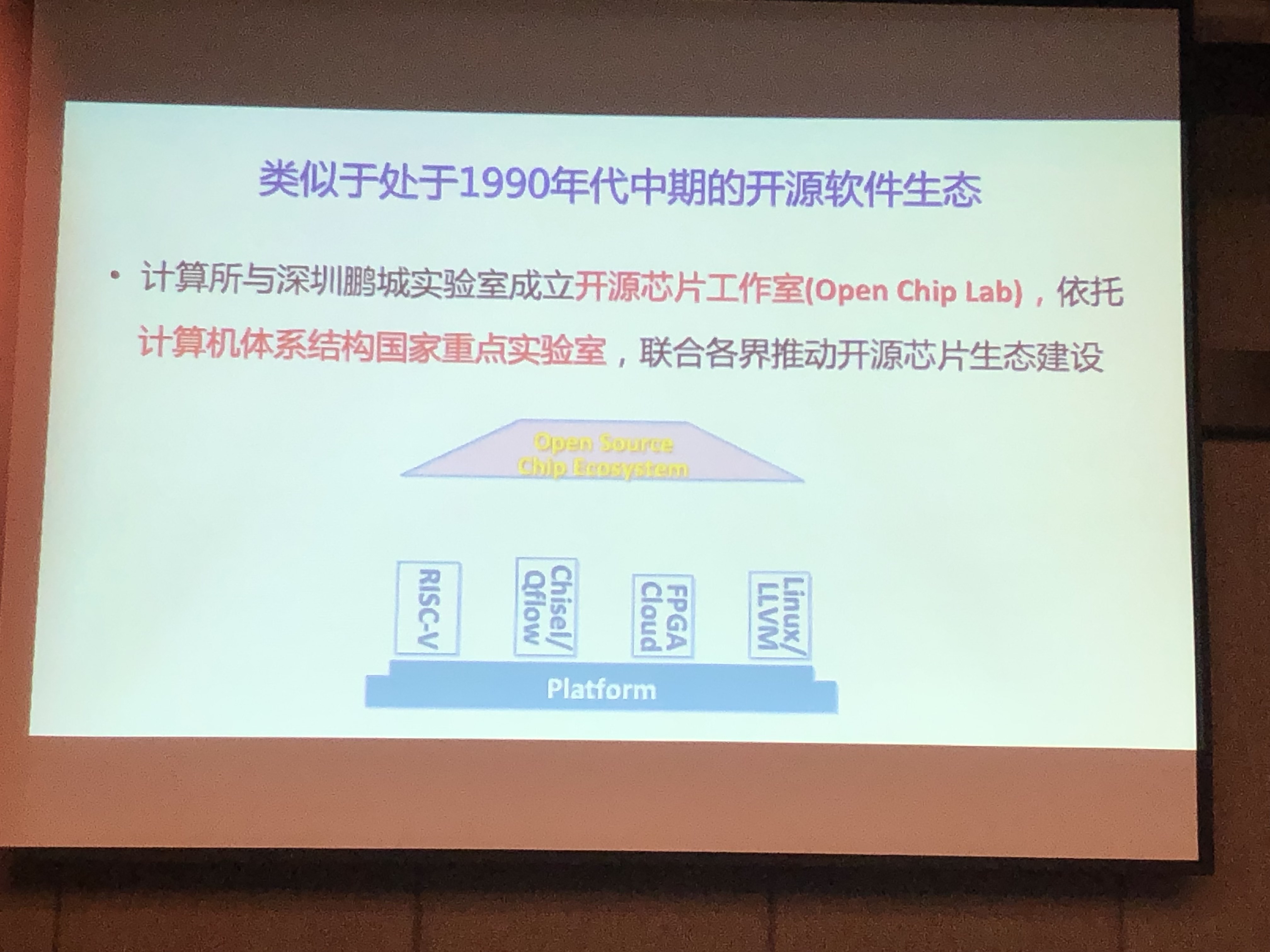
由于众所周知的原因,中美的科技壁垒迫切需要我们建立自主的芯片设计全栈。围绕RISC-V建立我们自己的生态,开源EDA是最重要的一步。
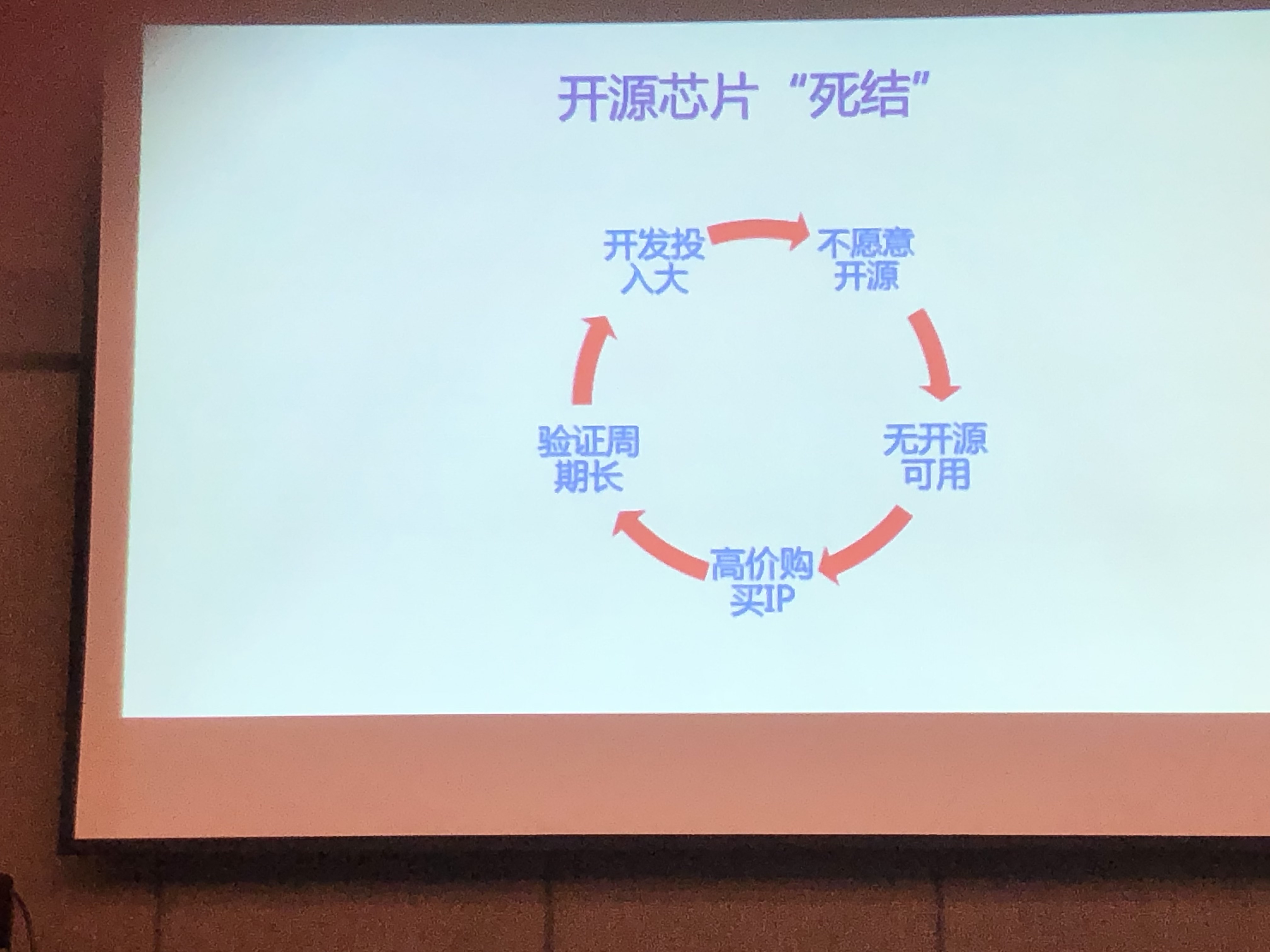
中国芯片挑战与机遇
- 优秀人才不足
- 芯片开发门槛高
- 流片成本
- 开发验证周期长
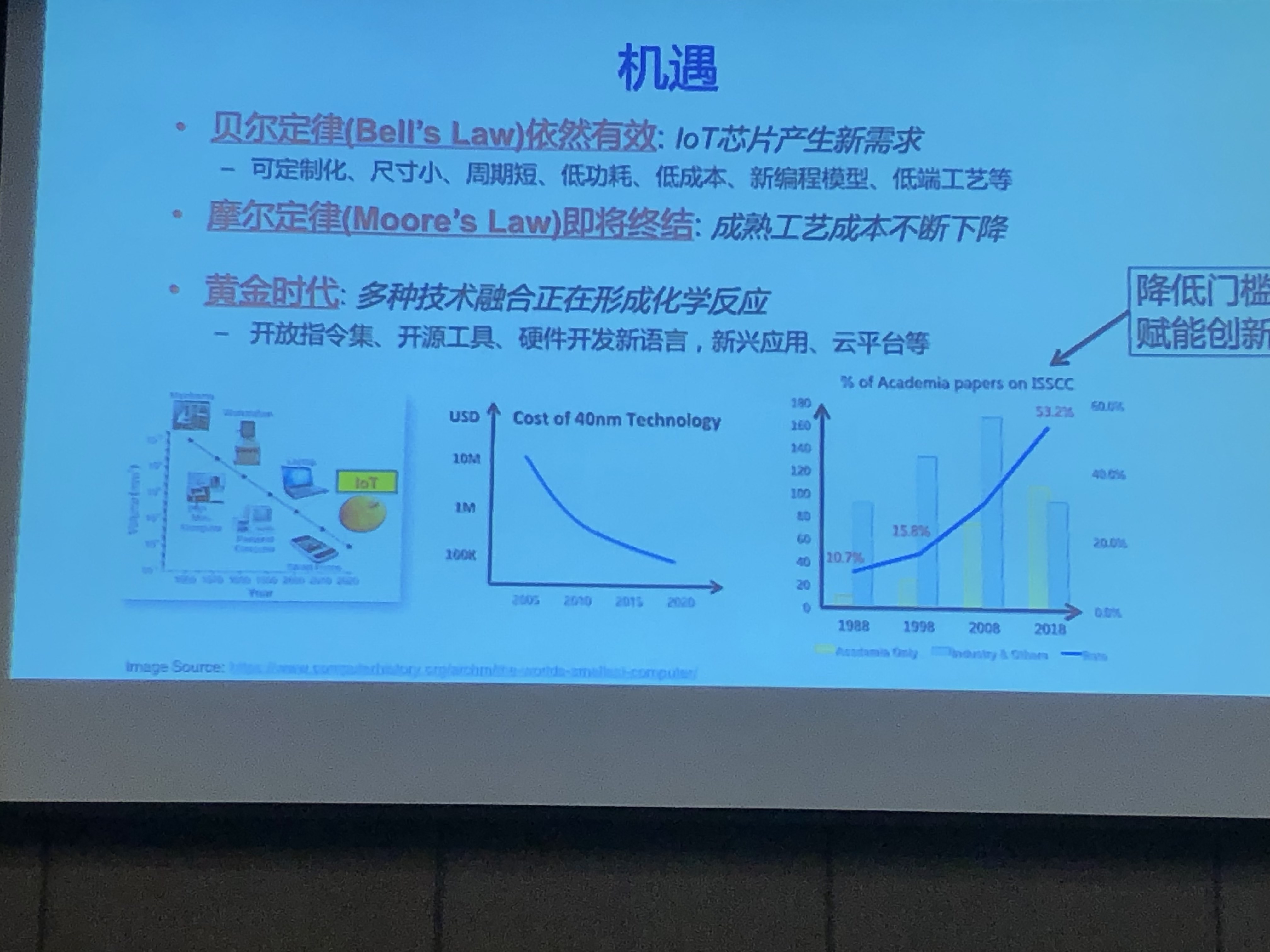
- 机遇
- 贝尔定律依然生效:IoT芯片需求强劲
- 如果保持计算机能力不变,每18个月微处理器的价格和体积减少一半
- 摩尔定律即将总结:成熟工艺成本不断下降
- 集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍
- 开源技术的黄金时代
- 贝尔定律依然生效:IoT芯片需求强劲
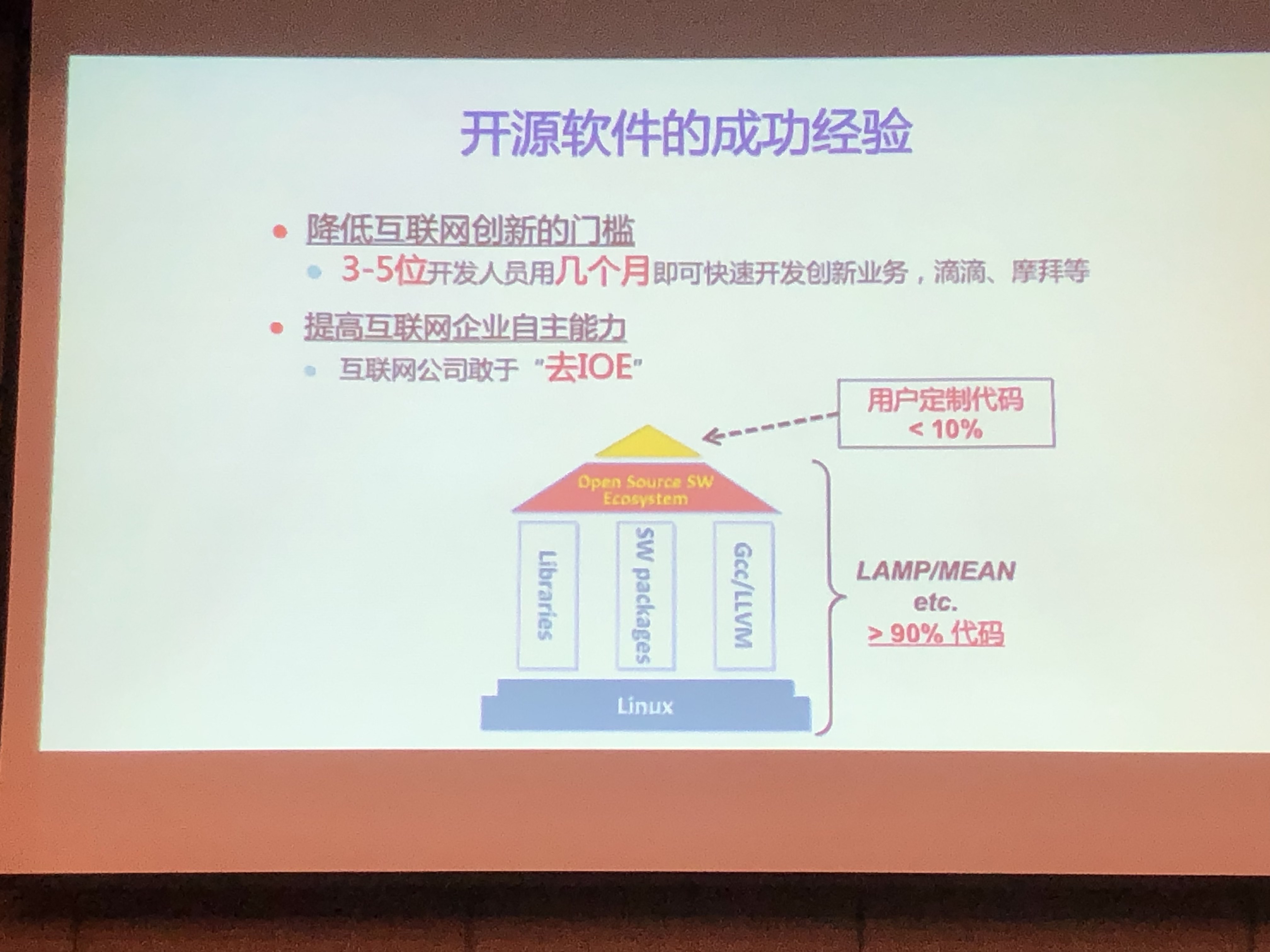
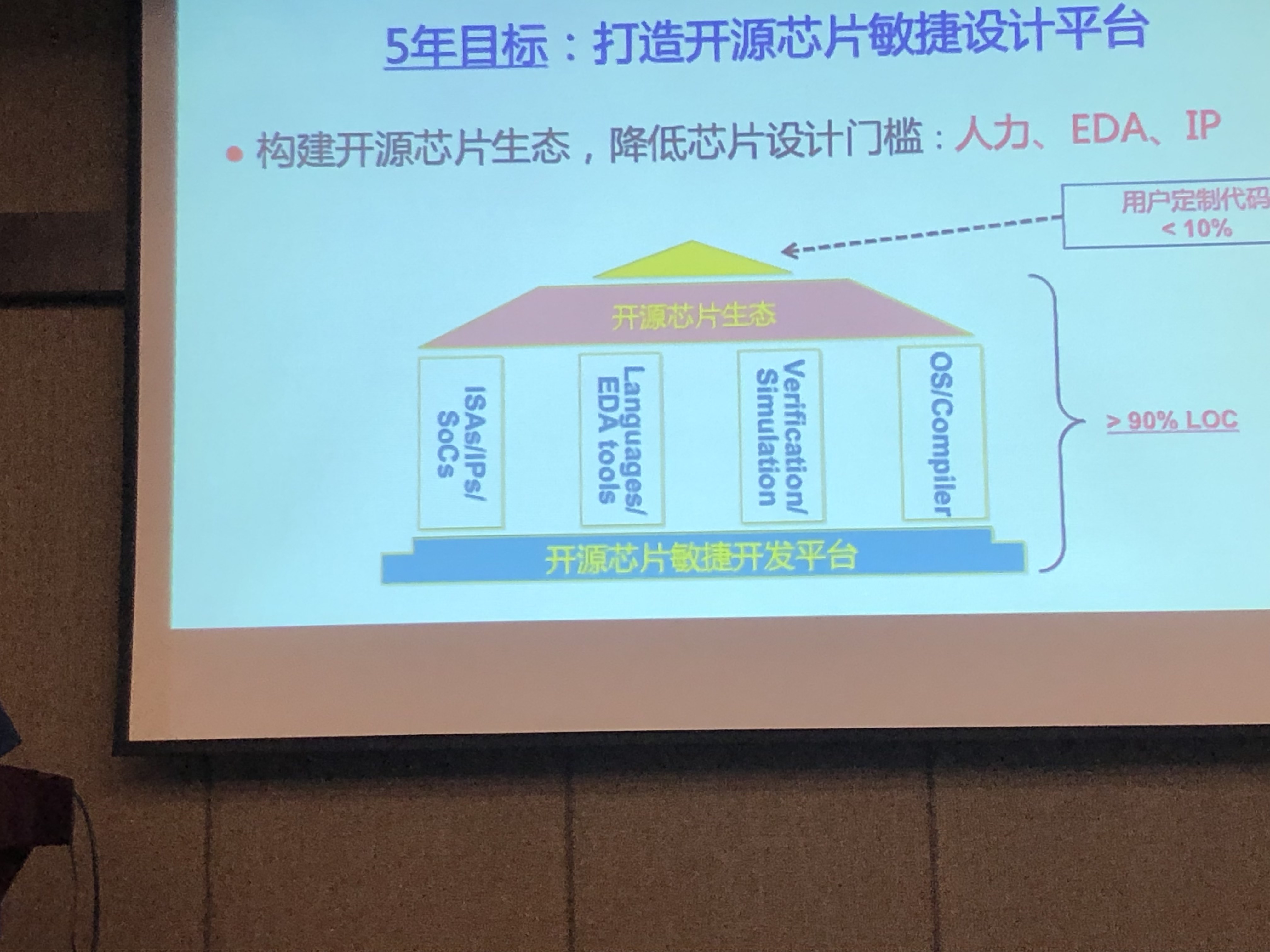
开源芯片敏捷设计平台:用户定制代码小于10%
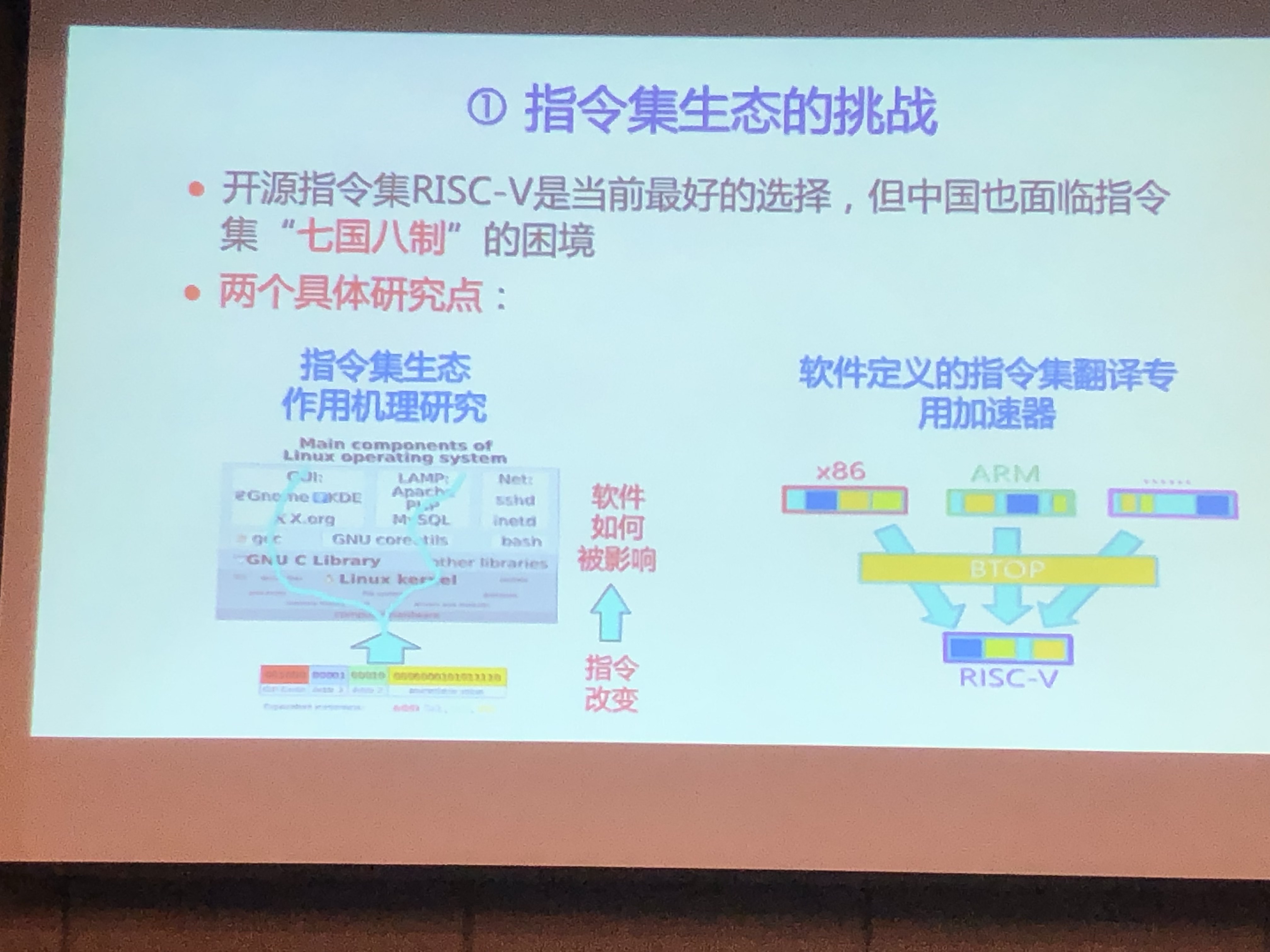
- 指令集生态RISC-V
- 指令集生态作用机理研究
- 软件定义的指令集翻译专用加速器
- 开源EDA工具链
- 已存在一系列开源EDA组件,可实现从Verilog到GDS版图的整个流程
- 欠缺:稳定、快速、高质量、维护
- 开源EDA项目:OpenRoad,VSDFlow,Qflow等
- 敏捷开发硬件描述语言:Chisel
- 比Verolog效率高14倍
- 代码量是Verolog的1/5
- 敏捷开发实践
- 基于云的仿真模拟
- 软件工具链
- 面向芯片:extended ISA
- 功能软件:languanges,lib,jvm
- 面向用户/程序员:APIs
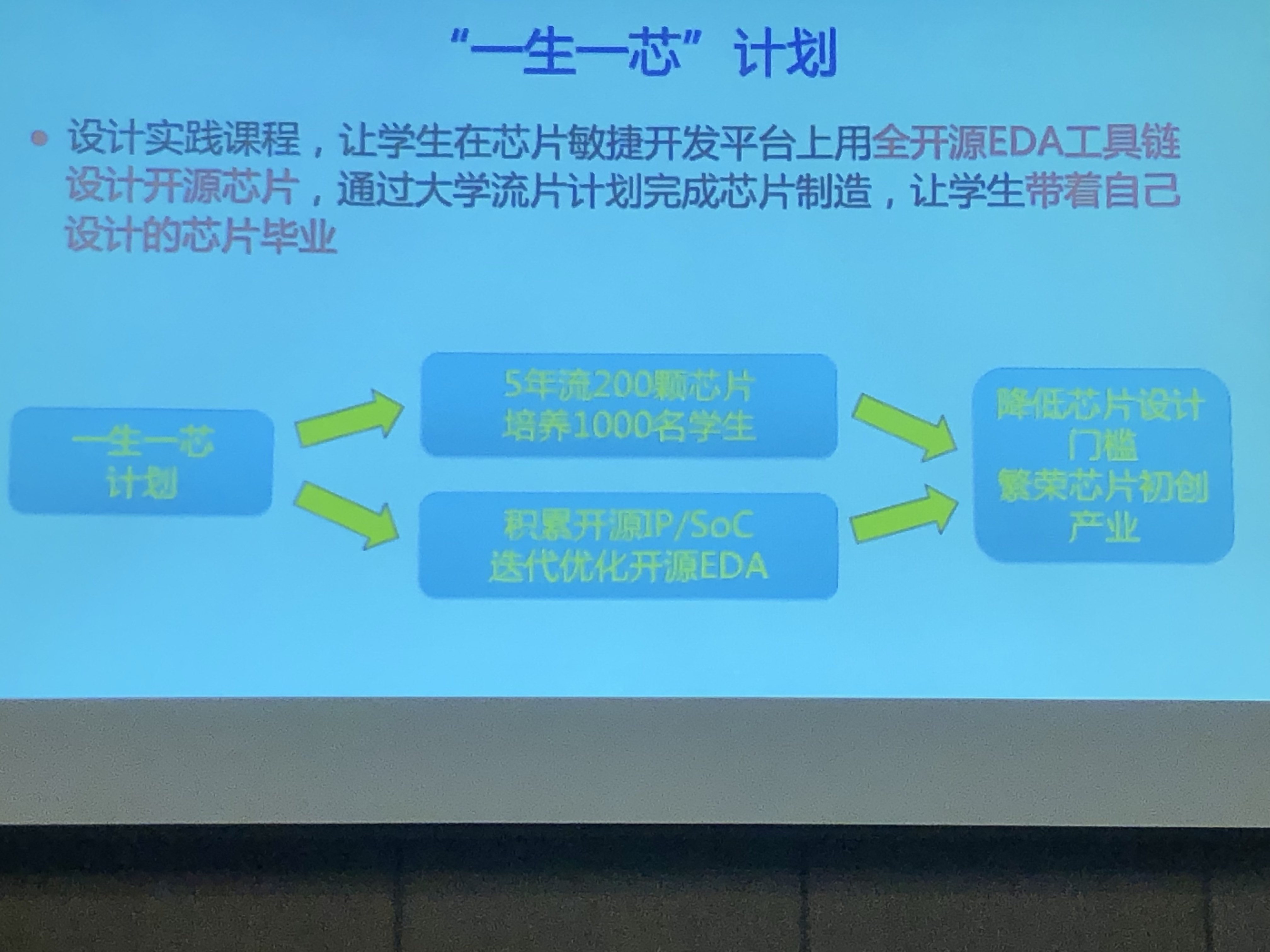
- "一生一心计划"
敏捷开发规划
- RISC-V联盟
- 2030 "三步走"规划
- 开源SOC
- 用开源工具链构建SOC
- 用开源工具链自动化构建开源硬件
- 开源用户风险分析与对策建议









会议总结
CFTC2019会议的报告还是非常精彩的,可重构计算、存算一体化、图计算等新型计算机体系结构为突破冯诺伊曼结构瓶颈带来了希望。清华大学汪玉教授的容错神经网络软硬件协同设计令人耳目一新,受益匪浅;中科院计算所王颖研究员的认知存储器应该是未来产业届存储发展的一个趋势;清华大学尹首一教授在可重构计算架构上研究深入,从软件栈到多款芯片的发布,是国际一流水准。多位专家围绕RISC-V的开源EDA项目或者倡议是本次大会的最重要部分,在当前科技摩擦背景下,RISC-V联盟和开源EDA对我们树立自己的芯片生态,建立科技护城河是紧迫、前沿的科技规划。