前言
针对嵌入式感知与认知的处理器在过去10年中变化很大。随着CMOS工艺尺寸的减小,芯片的面积与功耗继续降低, 推动开发下一代人工智能处理器,应用到手势检测,目标识别与分类。
今年ISSCC2016展示了几款下一代处理器系统,包括头戴增强现实,意图预测辅助自动驾驶,微型机器人路径识别等芯片。同时,可编程深度卷积神经网络、KNN算法处理器被提出,用于构建计算机视觉、机器学习等应用。
A 126.1mW Real-Time Natural UI/UX Processor with Embedded Deep-Learning Core for Low-Power Smart Glasses
摘要
《一款功耗126.1mW基于深度学习的低功耗智能眼镜实时处理器》的作者是韩国科学技术院的Seongwook Park。可穿戴头戴式显示器(HMD)智能设备正在成为智能手机的替代品, 其使用方便,适用于各种高级应用比如游戏和增强现实。大部分当前的HMD缺少丰富的应用接口,小容量电池,重量大;针对这一现状,论文提出基于嵌入式深度学习引擎的低功耗自然用户逻辑(UI/UX)的HMD处理器(图1所示)。
论文主要贡献
- 如图2所示,5级流水的手势分割内核(PHSC),采用基于移位寄存器的立体流水线结构,减少片外访存带宽
- 用户语音激活系统(USSC),监测用户声音自动激活系统,降低功耗
- 嵌入深度学习处理内核,PVT鲁棒随机数生成器(TRING)实现dropout;系统具有学习或推断两种模式
- 时间驱动的门控时钟调度方案(ECGS),当没有手势或语音的时候 ,锁定系统戏始终,降低功耗
点评
如图3所示,论文提出智能眼镜实时处理器,用于手势识别和语音识别。传统的头戴显示系统通过凝视(gase)方法实现用户接口,这种方法需要冗长的凝视标定(gaze-calibration),大大降低了自然的用户接口和体验。论文通过深度学习和手势分割实现头戴显示系统,实现2.6%的错误率,功耗降低了45.4%。



A 502GOPS and 0.984mW Dual-Mode ADAS SoC with RNN-FIS Engine for Intention Prediction in Automotive Black-Box System
摘要
《一款性能502GOPS、功耗0.984mW的双模式辅助驾驶RNN-FIS意图预测系统》的作者是韩国科学技术院的Kyuho J. Lee。高级辅助驾驶系统系统(ADAS)(图4)被用于碰撞警告,紧急制动,自适应巡航,车道保持等场景。论文实现基于RNN的双模式辅助驾驶SOC系统(图5),在d模式下实现高性能辅助驾驶,P模式下低功耗泊车。
论文主要贡献
- 大部分ADAS使用半全局匹配(SGM)实现高精度的距离估计,但是实现SGM的SOC需要巨大的访存带宽支持。论文实现分片流水的SGM处理结构,减少带宽需求。
- 大规模并行的RNN-FIS引擎,实现d模式下高性能的行人意图预测
- 混合模式的RNN-FIS引擎,实现P模式下低功耗的泊车
结构
所谓意图推断(Intention Prediction)指车辆行驶时判断前方行人是否为走到车辆前面,避免碰撞(图4)。图5所示的ADAS处理器包括7个加速器和一个IPE,每个部件用于不停的辅助功能。在d模式下,SGM处理器(SGMP)计算目标距离, 光流处理器(Optical flow processor:OFP)计算目标的空间特征、追踪目标,然后区域分割处理器(region-of-interest generation processor:RGP)裁剪图像(保留有用信息)以降低计算量;当目标检测处理器(object detection processor:ODP)确定目标之后,运动补偿处理器(ego-motion compensation processor:ECP)将2维图像转为3维真实世界的信息,IPE预测或判断目标是否会走到车辆前面,同时碰撞的风险。在P模式或泊车模式下,光流处理器追踪目标空间特征,IPE预测车辆是否会撞到目标。
双目立体视觉系统(深度计算):图6为任务层次(task-level)的3级分片流水SGMP处理器,其包括代价生成器、代价聚合器、非一致生成单元。摄像头采集输入图像(双通道),代价生成器生成census代价,聚合器利用64个PE并行计算64个非一致性。每两个聚合器同时计算8个不同的角度(0,45,…,315度),最后生成深度图(depth map)。由于深度图太大(14MB)不能完整放到片上,所以处理器基于8×8的分片计算,将访存降低了85.8%(28.1MB/frame降到4MB/frame)。具体的SGMP算法可以参考图7。
图8介绍了意图预测处理器(IPP),IPP将4层的RNN神经网络连接到模糊推断系统(fuzzy inference system)构成模糊神经元电路系统即RNN-FIS。输入(St,St-1,…,St-6)为目标物体的历史轨迹,RNN-FIS预测目标的下四帧轨迹。专用的矩阵处理单元(matrix-processing unit:MPU)加速RNN计算。MPU包含8个SIMD扩展集,可以同时计算32个8bit、16个16bit、8个32bit。模糊推断器根据不同的路况执行64个不同的模糊规则。IPE可以以1.24ms的延迟同时预测20个目标。
点评
针对辅助驾驶系统,论文实现基于SGM,RNN-FIS的ADAS SOC系统。通过任务级流水线技术降低片外访存与功耗,大规模并行计算使系统的预测延迟很低,RNN-FIS实现了20%的错误率。该系统能够满足实际的辅助驾驶应用场景。





A 0.55V 1.1mW Artificial-Intelligence Processor with PVT Compensation for Micro Robots
摘要
《一款0.55V 1.1mW针对微型机器人的PVT补偿人工智能处理器》的作者是韩国科学技术院的Youchang Kim。人工智能微型机器人可以用到无人机等多个领域,认知在微机器人自动导航中扮演着重要的角色(图9)。特别是路径规划和避障要求50ms内快速迭代10,000次搜索。由于需要在环境中快速移动,同时电池容量小,微机器人要求比Cortex-M3 10倍低的功耗、100倍的计算速度。针对这一问题,超低功耗、高性能的人工智能处理器(AIP)被提出,。
论文主要贡献
- 8线程搜索树处理器(TSP)以及增强学习处理器(RLA),用于实时决策处理
- 3级人工智能缓存,最大化片上缓存项,最小化外存访问,减少重复的计算
- 片上PVT检测补偿电路,增强系统在高频率或低电压状态下的稳定性
结构
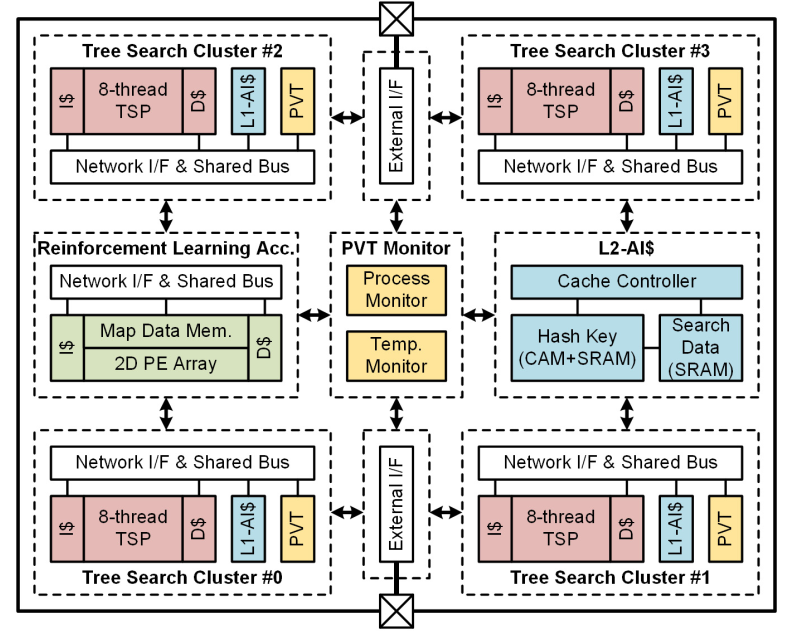
如图10所示,系统包含4个搜索树簇(TSC),一个增强学习处理器,一个高速缓存和一个全局PVT补偿电路。搜索树簇由TSP和数据缓存、指令缓存、人工智能缓存构成。4个搜索树簇并行执行路径规划,增强学习处理器根据机器人之前的行动预测下一步的路径同时避过前方的障碍物。
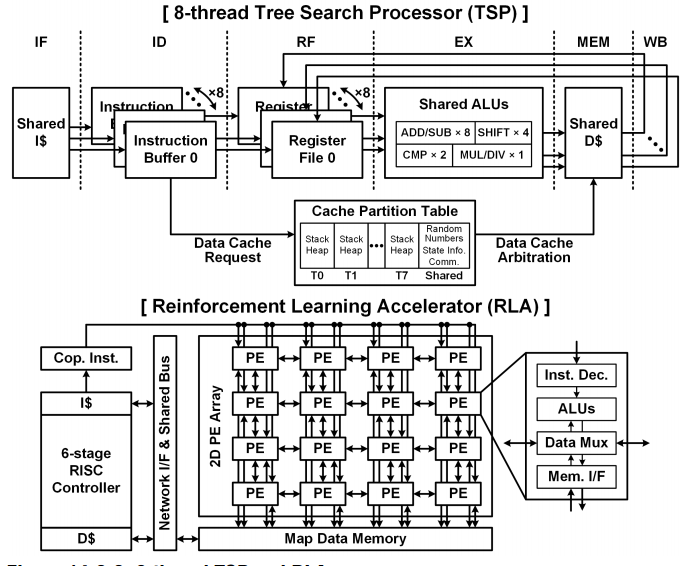
TSP通过多线程体系结构加速迭代深度算法(Iterative-deepening algorithm:IDA),IDA构造关键路径的树并使用启发式代价函数评估每条路径的代价,找到最优的路径。图11所示,8线程的并行度可以帮助机器人同时求解8个方向的最有解。RLA使用4*4的PE阵列更新路径,6级的RISC控制器保证整个系统的正确执行。
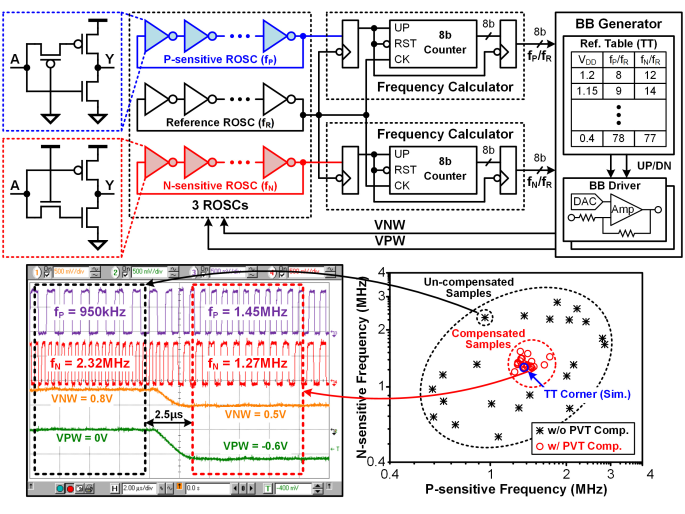
由于MOSFET偏移,低功耗的操作会随着电压的降低性能下降。为了补偿性能,VNW和PVW会被钳制在VDD和GND附近,如图12。最终论文的人工智能处理器实现在0.55V搜索能耗比79nJ/Search,1.2V下每秒470,000次路径搜索,功耗是Cortex-M3的11分之一,性能达到276倍。

点评
针对微机器人的路径规划问题,论文提出能耗比极高的人工智能处理器,使用多线程TSP同时迭代8个方向的路径求解,利用增强学习处理器更新路径,进行避障。路径规划问题这两年在机器学习领域是很热的研究方向,路径规划的加速器不仅在学术领域有价值,同时在工业界也要广泛的应用前景。
A 1.42TOPS/W Deep Convolutional Neural Network Recognition Processor for Intelligent IoE Systems
摘要
《一款针对物联网系统能耗比1.42TOPS/W的深度卷积神经网络识别处理器》的作者是韩国科学技术院Jaehyeong Sim。对于物联网设备来说,采集大量的图片、音频数据并发送给数据中心做认知处理,受实际的网络、延时等限制,是一个挑战。针对这一问题,论文提出卷积神经网络加速器用于物联网设备的实时认知处理。
论文主要贡献
- 针对CNN优化的神经元处理引擎(NPE)
- 双精度乘法累加单元(DRMAC)
- 片上内存优化方案(数据重用)
- kernel压缩,减小访存
结构
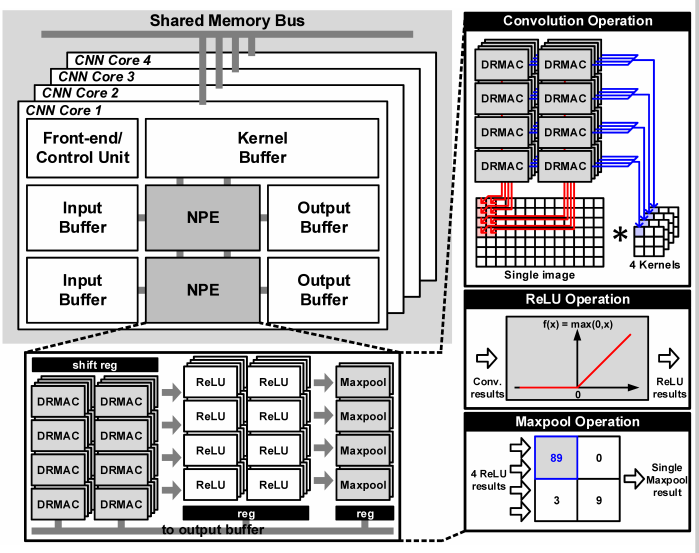
如图13所示,处理器包含4个共享内存总线的CNN核,每个核包含2个NPE、2个输入输出buffer、2个kernel buffer。输入输出buffer存放输入输出数据,kernel存放权重weight,这里的权重有两个NPE共享。一个NPE包含32个DRMAC(每8个DRMAC为一组,共享权重)、32个ReLU,4个max-pooling。计算方案如下:一组DRMC共享权重计算一个输入map上的不同kernel,不同的组共享输入数据计算不同的输出map,这样相当于32个卷积核同时计算,计算ReLU激活输出32个点(输出层上4个map,每个map8个点)。这里的计算方案我认为是同时按照输入的map(不同kernel共享权重)和输出的layer(不同map共享数据)来计算,这样的好处是最大化数据重用,同时复用了输入数据和权重,缺点是调度会更复杂(实现麻烦)。因为输出32点按照8个深度layer8个map排列,所以max-pooling单元只有8个,计算8个pooling点;这里的结构相当于把卷积、激活、pooling放在一起做,加速器的粒度比较大。
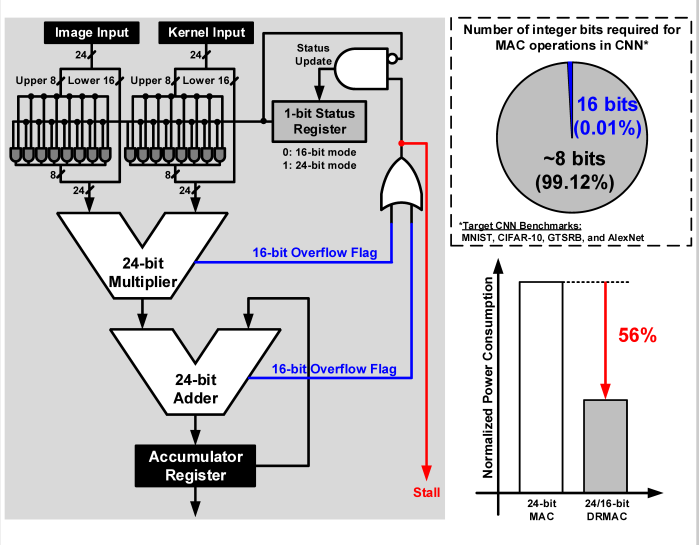
图14为双精度度乘法累加器DRMAC。DRMAC支持两种数字精度方案,第一种是Q16.8,提供更高的计算精度。另一种是Q8.8,由于99%的CNN计算只需8bit整数就可以满足精度要求,所以这种方案可以降低功耗,减小计算量。同时DRMA提供溢出处理方案,如果Q8.8溢出就转为Q16.8方案。论文称这种DRMAC方案比起24bit的定点方案减少了56%的功耗。
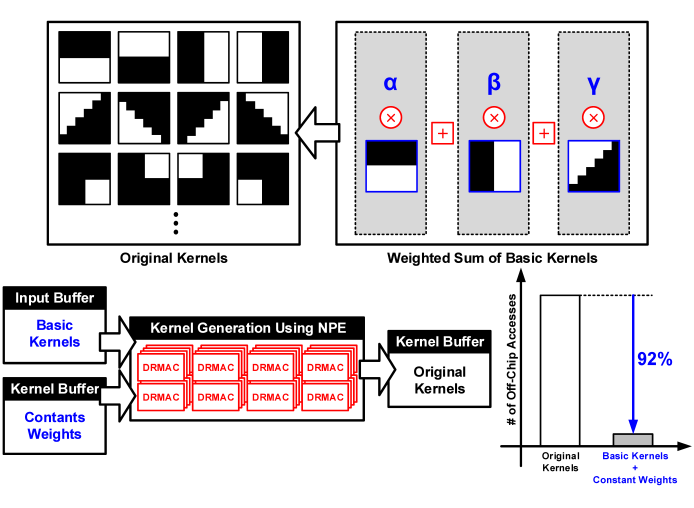
为了进一步优化访存问题,PCA压缩方法被引入,如图15。利用kernel之间的相关性,可以只存储基础kernel,其他kernel可以用PCA算法在基础kernel上推断出来。这种方法减小了92的片外访存,只损失了0.68%的精度。
性能
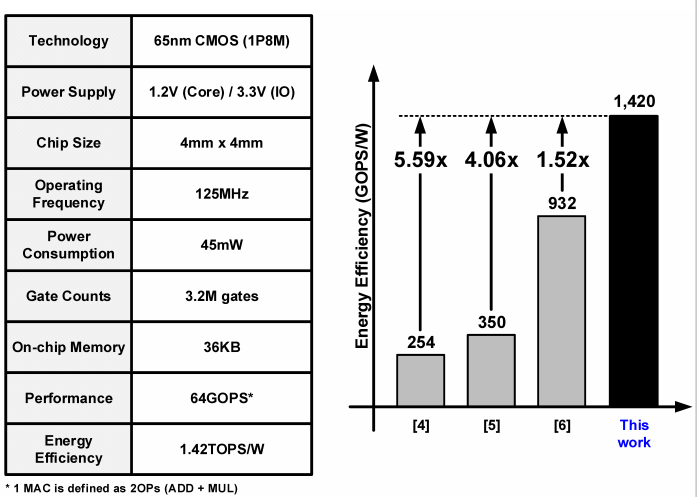
性能如图16所示,系统包含3.2M逻辑门,65nmCMOS工艺,125MHz、1.2V电压状态下实现能耗比1.42TOPS/W。
点评
论文加速器并行度很高428*4=256MAC,可以一次性计算卷积,激活,池化,计算粒度较高。同时卷积计算方案最大化利用数据和权重复用,令人眼前一亮。
Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks
摘要
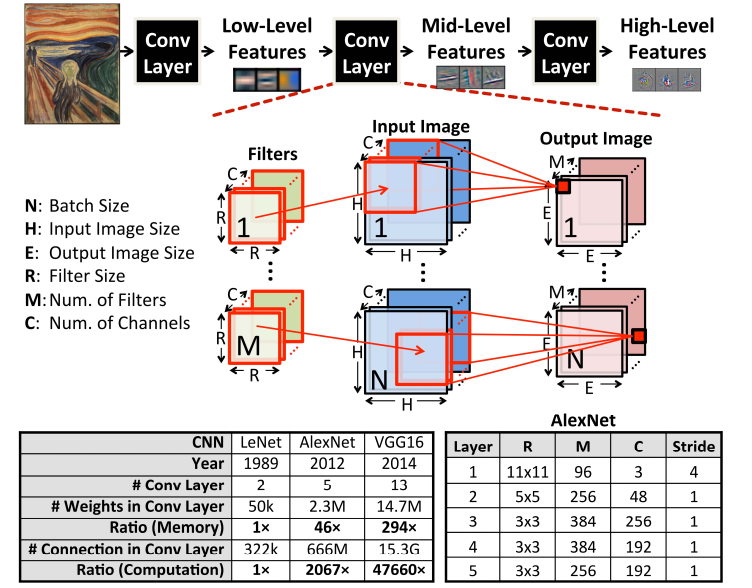
《一款高能耗比的可重构深度卷积神经网络加速器》的作者是MIT的Yu-Hsin Chen。为了实现高精度,CNN网络使用更多的层数以及大规模的参数,如图1所示。AlexNet包含230万(4.6MB)权重和6千6百万次MAC计算;VGG16包含1千4百万(29.4MB)权重及1百五十亿次MAC计算。这样的规模导致大量的计算和持续的数据移动,消耗大量功耗,给加速器的设计带来挑战。针对这一问题,论文提出一种CNN加速器,支持多种网络,优化数据访存,实现高精度的同时消耗最小的能量。
论文主要贡献
- 有效的数据流动架构(脉动阵列),最小化数据移动,最大化数据重用并支持不同的网络模型
- 通过跳0避免冗余数据移动和计算,同时使用数据压缩技术减小片外访存
架构
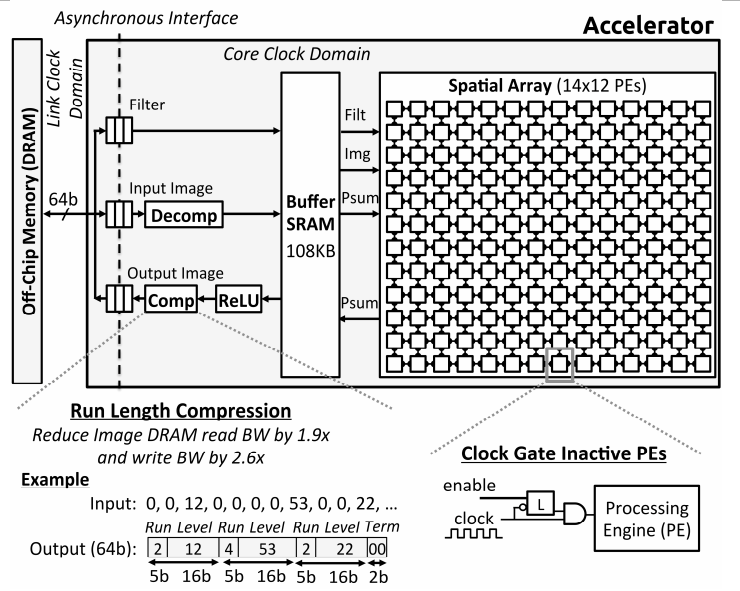
系统顶层架构如图18所示,包含数据压缩解压模块,ReLU,108KB的片上SRAM,14×12=48个PE。基于字长的压缩数据从DRAM经过解压模块移动到SRAM上,PE阵列计算卷积后将数据暂存到SRAM上,经过ReLU激活函数和压缩,被搬回DRAM。基于字长的压缩方法可以减小平均2倍的访存带宽。
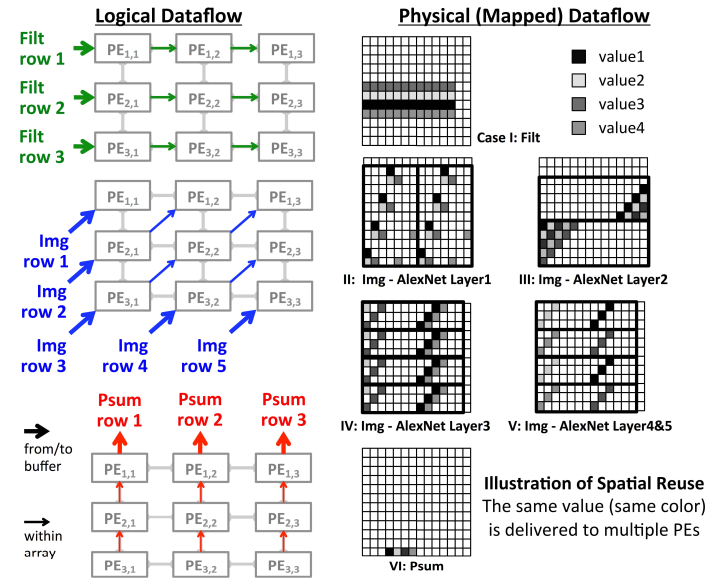
卷积计算的过程如图19的脉动阵列所示。1)如果kernel size(filter weight总数)与阵列的行数相同:权重从阵列左到右边流动,数据从左下角到右上交以对角线方式移动,同时部分积Psum从底部到上部移动(PE计算结果上移并累加)。这里的意思是这样的:权重开始在最左边的一列,数据也在最左边的一列,那么最左边的一列就能计算一个完整的kerel(kernel size与行数相同);权重右移相当于权重共享,数据对角右移相当于数据共享(为什么不直接右移是因为kernel与kernel之间有部分重叠数据,对角右移相当于只共享重叠部分数据并灌入不重叠数据,直接右移代表共享所有数据),这样第二行就相当于计算了偏移stride的kernel,后面依次类推;在数据移动到第二列时,最左边新的权重和数据进来(类似于流水线),第一列开始计算新的kernel(不同的map);最后部分积由下到上移动并累加就计算完一个输出点。这种方法十分巧妙,借用脉动流水结构,使数据和权重同时重用,并且带宽需求量小,并行度高(第一行的每一个PE计算一个输出点)。2)如果kernel size与阵列的行数不相同,那么数据映射或流动的时候需要折叠和复制,对于kernel size过大的情况,将数据拆成两部分来做(折叠);对于kernel过小的情况,将数据复制一部分与阵列长度匹配,同时多的一部分数据对应的阵列不工作(时钟锁定CLock Gated)。
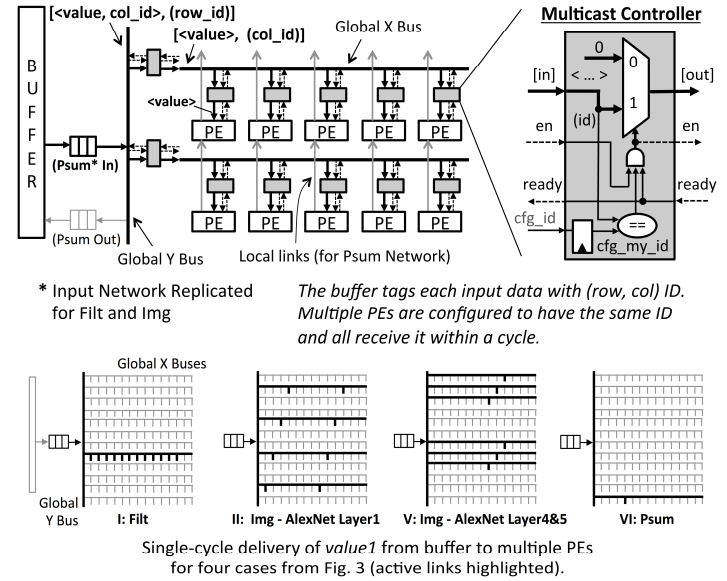
为了支持数据流的移动,每一个PE可能被kernel数据映射任一部分,同时同一数据可能被多个PE共用。论文提出一种NoC互联网络,支持这种复杂的映射,如图20所示。NoC将阵列描述为一个Y坐标,x坐标,每个PE被分配一个ID(row,ID)。如果多个PE设定为相同的ID,那么一个数据可以在一个周期被发送到所有相同的目标ID上;buffer中的每个数据都被分配了一个目标PE的ID,数据流动的时候根据ID分配,当所有的目标ID PE处于ready状态时,数据开始映射。
PE的具体结构如图21所示,是一个3级流水结构,包含Image Pad、Filer Pad、Psum Pad、乘法器、累加器。乘法器与累加器执行卷积运算,Image Pad、Filer Pad和Psum Pad分别用于暂存图片数据、权重和部分积,用于接受和输出到相邻PE的数据。同时PE配备时钟门控电路,在PE不工作时可以关闭,能够节约45%的功耗。
性能

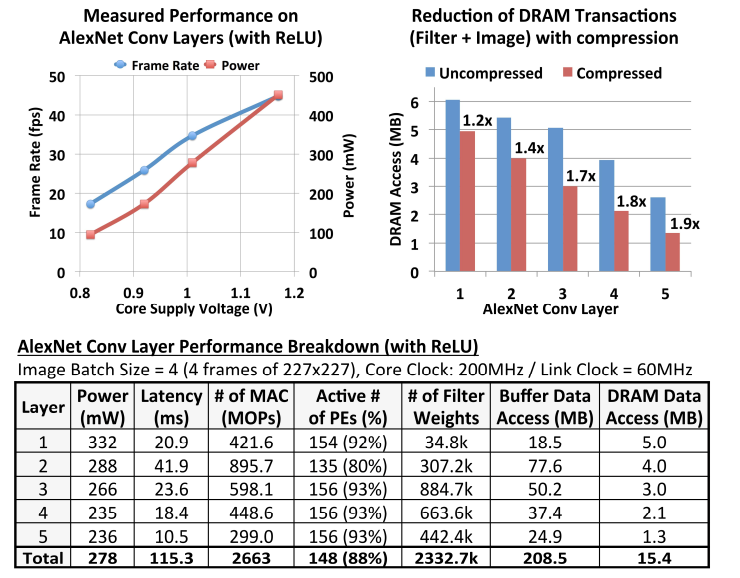
加速器的性能如图22所示,在200MHz、1V的状态下跑5层AlexNet网络帧率高达34.7fps,功耗低至278mW。PE、NoC、buffer分别消耗了77.8%、15.6%、2.7%的功耗。
点评
个人认为,MIT这篇论文可以说是DIANNAO系列以来结构创新最大的神经网络加速器。创新的脉动阵列PE结构,不仅保持了较高的并行度,同时重用权重和数据,使访存需求变得最小。如果不使用脉动结构又想复用权重数据,带宽会很大(比如上一篇文章)。NoC和整个系统的调度器在工程上也是实现的难点。个人估计,这篇文章会成为以后加速器设计人员必须借鉴的范例。